
Engineering
Handling asynchronous operations with Flowable – Part 1: Introducing the new Async Executor
The Flowable Async Executor (also known as the Job Executor) is a crucial component of Flowable. At its core, it is a reusable, standalone component running within the various engines of Flowable that provides a way to asynchronously execute logic.
In the last few weeks, we’ve been working hard to implement the “next generation” of the Async Executor architecture. We have benchmarked this implementation (teaser: it’s awesome) and are eager to share the results with the community. There’s a lot of content to cover and this blogpost is the first in a series:
In the first part, the post you are reading right now, we’ll get everyone aligned by explaining the purpose of the Async Executor.
For the second part, we’ll look at the various subcomponents of the Async Executor and explain how to configure them.
With the third part, we’ll publish and discuss the benchmark results using the various concepts and configuration options covered in the previous parts.
Lastly, in the final part, we’ll look at the evolution of the architecture over the years and how we arrived at the new improved architecture.
Before diving deeper, let’s first get everyone on the same page and describe what it means if we talk about this “Async Executor”.
Purpose of the Async Executor
The Async Executor is used in pretty much any realistic BPMN or CMMN model. Whether it is about user-driven flows or large (micro-) service orchestrations, chances are high you’ll be using the Async Executor. If we then tease above that we have finalized a more scalable and performant implementation … it is good news for everyone. A faster Async Executor means a higher throughput of flows, cases, transactions. Which should be of significance to anyone.
The main purpose of the Async Executor is to pick up jobs and execute them. To understand what a job is, let’s have a look at the following BPMN model (the concept’s the same for CMMN):
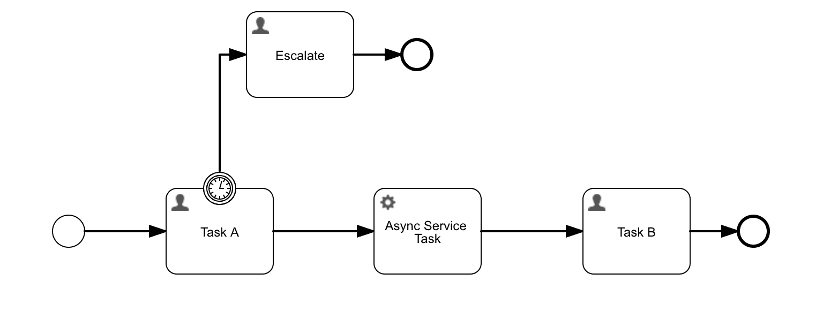
There are two constructs in this model that will make use of the Async Executor: the boundary timer event on the first user task, Task A, and the service task, Async Service Task, in the middle.
When an instance of this BPMN model is started, a new user task, Task A, is created. On that user task, there is a boundary timer event that interrupts the task and follows the path to escalation. Behind the scenes, due to the boundary timer event, a timer job is created at the same moment that the task is created.
The Async Executor is now responsible for:
Detecting that this timer event should trigger when the due date of the timer is reached.
Executing the user task interruption and taking the escalation path, asynchronously.
The detection of jobs is called acquiring in Flowable terminology (remember this word, it’ll be important for later). Both the acquisition and execution of jobs happens asynchronously, hence the name Async Executor. In this example, this means that when the timer event is triggered, the Task A user task is deleted and the Escalate user task is created in the background. There’s no user interaction triggering this. A user will only see this when they refresh their task list: the old task will be gone and the new task will now visible.
If the Task A is completed, and the timer didn’t trigger, the process instance continues and arrives in the Async Service Task. Let’s assume that the async property has been set to true for this task.
At this point, the Async Executor will now:
Execute the logic in the service task.
Continue the process instance afterward.
Both points happen asynchronously, in the background. In Flowable terminology, an async job is created by the Flowable engine when the service task is reached. As such an async job can be seen as a request for asynchronous work, containing the instructions to execute the logic and continue the instance.
However, the Async Executor will need to acquire this job first. Once the job is acquired, it is scheduled for execution. In this example, this means that when the user completes Task A, the task list will be empty until the moment the service task is processed, and the Async Executor has moved the process instance into Task B.
Asynchronous job requirements
Imagine that the service task here is something that takes a bit of time (such as generating a document based on form input). If we didn’t make the service task asynchronous, the user would see a loading spinner on the screen until the logic is executed and the next task is ready. In that sense alone, making something asynchronous can mean a big boost for the user experience.
Asynchronicity is not only useful when dealing with models involving human interactions. For service orchestration, where multiple services are integrated using a BPMN model, making these calls asynchronous often will mean a speedup in throughput. Take the BPMN model below, which only consist of calls to other systems:

Making these tasks asynchronous will mean four paths will be executed independently, in the background. If they were synchronous, the total execution time would be the sum of the execution time of all paths. Asynchronously, the total execution time would be the maximum execution time of the slowest path (assuming perfect concurrent asynchronous execution).
Of course, if the requirements were only about executing work asynchronously and determining when a timer should fire, regular thread-pooling and its related execution services as provided by the JDK would suffice.
However, for the use cases that are possible with Flowable, additional functionality is needed:
Jobs need to be persisted and survive a reboot: if a Flowable instance goes down (for example, due to the underlying system crashing or something else), the job should not be lost.
Further than that, it should be picked up automatically when an instance comes online again.
In case of failures, whether caused by Flowable or an external system, the job should be retried automatically without needing manual intervention.
The Flowable engine can scale out load by adding more node instances. If on one particular instance the Async Executor cannot handle the asynchronous work, another instance in the cluster should pick up this job and execute it. This means that the acquiring of jobs is designed in such a way to function properly in a multi-node setup.
It’s clear from this list that a simple thread-pool solution won’t cut it.
The Async Executor has been part of Flowable from the very beginning (dating back to the first Activiti release, from where Flowable is forked). In fact, the Flowable core developers have worked on and improved the Async Executor for over a decade. In those years, the architecture has evolved, always being backward compatible with the previous iterations.
The New Async Executor Architecture
It took many prototypes, countless hours of discussions and an equal amount of benchmark experiments before we got to the current implementation. In true open source fashion, you can already see the code in all its glory in the following pull request:
https://github.com/flowable/flowable-engine/pull/2844/commits
As happened in the previous generations, we were pushed by both the community and enterprise users that were using Flowable in some very interesting and highly-demanding use cases, leading to a rethinking of the architecture. This new architecture is the 4th generation of the Async Executor for us. We’ll talk more about the history of the previous generations and how we got to the current one in part three of this series.
Without spoiling too much (hey, we still want you to read the next parts ;-)), this new architecture is all about lowering concurrency and contention on the job tables. That, and finding some nice improvements as a side-effect along the way. By introducing a technique we dubbed the global acquire lock, we are able to push the limits of the Async Executor. The following diagram gives a high-level (sales-y) picture of the implementation:

Don’t worry yet about what the symbols mean on the right-hand side, we’ll discuss these in detail in the next part of this series. For now, it suffices to say each rectangle is an Async Executor containing (from left to right): acquire threads, an internal queue and a threadpool of execution threads.
Through various experiments, we discovered that concurrency on the tables was the number one cause of performance degradation, especially when additional Flowable engine instances were added. Often, the acquiring of jobs was the underlying culprit. In a nutshell, as we’ll give all the details in part 4, the new architecture is all about using the global acquire lock to make sure only one instance only can access the data at a given time. Then making sure that the execution threads are never starved for work – by tweaking various parameters of the Async Executor covered in part 2 – this speeds up throughput tremendously.
Next Up
In this first part of the series we needed to get the scene set for the following, more detailed, posts. With the basics out of the way, we can now go full speed on the stuff that matters: how to configure things and the benchmark numbers!
More Details
Already interested in reading more about the Async Executor?
The following two articles go deep (technically) into explaining how the Async Executor works. They were written a while ago, but they’re still an excellent explanation of many things going on when using asynchronous tasks in your models.


BPMN is dead, long live BPMN
Tools like ChatGPT can handle a variety of business tasks, automating nearly everything. And it’s true, GenAI really can do a wide range of tasks that humans do currently. Why not let business users work directly with AI then? And what about Agentic AI?

Measuring model complexity – Part 3: Introducing Complexity Analyzer
In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.

Measuring model complexity – Part 2: Putting theory into practice
In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.