
Welcome to the fourth and last part of the series on the new Flowable Async Executor. The journey so far has been quite an intensive one:
In the first part, the new Async Executor and related general concepts were introduced, needed to make sense of the subsequent posts.
The second part was all about zooming in on the details and configurability of the various components that make up the Async Executor.
With all that knowledge under the belt, it was now time for the key outcomes: in the third part we shared the benchmark results (and we were very pleased with them!).
When looking at the parts as laid out above, there’s one segue still missing: how we got to where we are today. What pushed us to the current implementation and why? How did we find the bottleneck(s) and how did we use that data to engineer a better approach? And, taking into account the first generation is more than a decade old, how did the Async Executor evolve while always keeping backward compatibility?
That’s exactly what we’ll cover in this part. We’ll take the opportunity to look back from the very beginning and reminisce about the various implementations that have come since. We’ve identified four generations of the Async Executor and we’ll look at them briefly in turn. As Flowable is a fork of Activiti, it means that the story will start with the first version of Activiti (version 5.0.0).
The first implementation was called the “Job Executor” at the time. It was a straightforward implementation of the requirements described in part two: jobs needed to be persisted, acquired, internally queued, executed and things should continue to work/be retried when errors happened.
In those days, all types of jobs: regular async jobs, timer jobs, suspended jobs and deadletter jobs were stored in one database table. The differentiation between those types was made in the queries that were done behind the scenes. For example, deadletter jobs were those that had no retries left, timer jobs were those with a specific type and due date, and so on.
One dedicated thread, the job acquisition thread was responsible for acquiring any type of job (async job or timer job) and passed those jobs to the internal queue, where execution threads took them from to execute them.
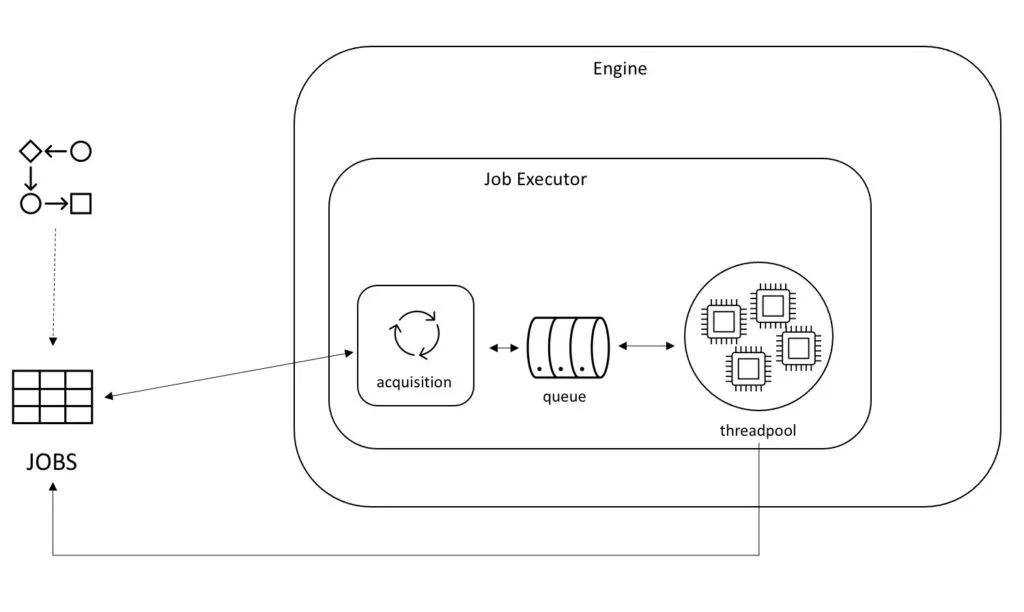
It’s worthwhile looking at the algorithm as it was in those days, because many of the high-level concepts are still visible today, even a decade later (which makes sense, if you take into account that even the code written then was already building on top of knowledge gained by building other, earlier systems).
Fetch a page of executable jobs. Executable jobs are those whose parameters match a set of states, taking into account type, due date, suspended state, and so on. One can imagine that the query was quite sophisticated to cover all use cases.
Try to lock each job, one by one.
This means updating the lock owner and lock expiration time columns in the job table row, using optimistic locking (confusingly, this is a different lock than meant by the ‘lock’ owner).
If an optimistic locking exception happens, this means another instance has already locked the job. This can happen in a multi-node setup.
If no optimistic locking exception happens, the job is passed further to the internal queue.
When the job logic executes without any error, the job is removed.
When an error occurs during job execution, the retries are decremented, and the lock owner and expiration time are cleared. Another job executor (or the same) can pick it up again now in an acquire cycle.
(This is a simplification of things. The real algorithm had way more details.)
Also note that the addition of the lock owner and expiration time concept in step 2 means that these states needed to be taken into account in step 1. After all, the job executor shouldn’t retrieve any job that is already locked by another instance. This means that the query needed to do a date comparison with the lock expiration time value, to determine if a job was ‘stuck’ (for example, due to a server crash).
As you can see from the algorithm description, the Job Executor was designed with a multi-node setup in mind from the get-go: before a job could be executed, it first needed to be ‘tied’ to a certain instance. This made sure that no job could ever be executed twice. Keep this in mind, as the concept of ‘locking’ or ‘tying’ a job to a specific Async Executor instance is crucial to the optimization that we’ve done in the most recent implementation.
The first generation of the Async Executor was obviously improved over the multiple releases that followed after the initial one, yet the fundamental architecture did not change tremendously.
At a certain point in time however, users were pushing the limits of what was possible with that architecture. Experimentation and analyzing benchmark data led us to the culprit: the queries for retrieving jobs and job data. It was discovered that, when the executor was severely pushed, the database responses would become slow and, in some cases, even swap to table scans instead of using table indices. Because all job data was stored in one database table and use cases had been added over the releases, the query had become quite elaborate at that point.
The solution was to split the job data into different tables, catering to their specific use cases, with the goal of making the queries as simple as possible. With such simple queries, the database would be able to provide the data in acceptable time. As such, the job table was split into four distinct tables: Async jobs; Timer jobs; Suspended jobs; and Deadletter jobs. Those tables are still there today in the current implementation.
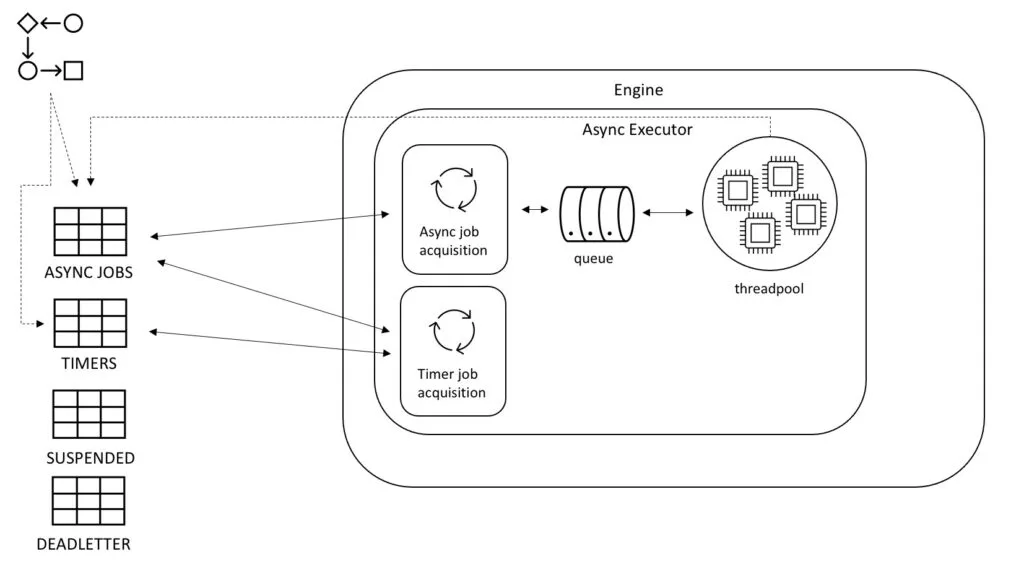
It’s clear how this simplified things:
Having the suspended jobs in a separate table meant that no checks on this state needed to be made anymore. While this did complicate the actual suspending (as data needs to be moved), the effect of having a faster query far outweighed the initial time investment.
A similar story for the deadletter jobs: when the acquisition didn’t need to take into account the fact some jobs could have failed, this simplified the queries and made them faster.
Timers are fundamentally different from async jobs. Timers can be in the table for a long time (even years). Async jobs, however, indicate that work needs to happen right now. By splitting off the timers into a separate table, the query for async jobs became much simpler, as the timestamp check on the due date could completely be removed. This did mean that timers need to be acquired differently from async jobs. For this purpose, there were now two acquire threads, one for each type.
Acquiring a timer became fundamentally different: when a timer job is acquired (and thus the due date is reached), it is actually transformed into an async job, which meant it is removed from the timer table and added to the async job table (indicating it’s ready to be executed).
All the above now meant that any new entry in the async job table indicated a job that’s immediately ready to be executed. No filtering needed to happen (except for checking whether another instance had taken it) and thus the query became simple and fast. Conceptually, it was comparable to a new message arriving on a message queue: when it arrives, it’s ready to be consumed.
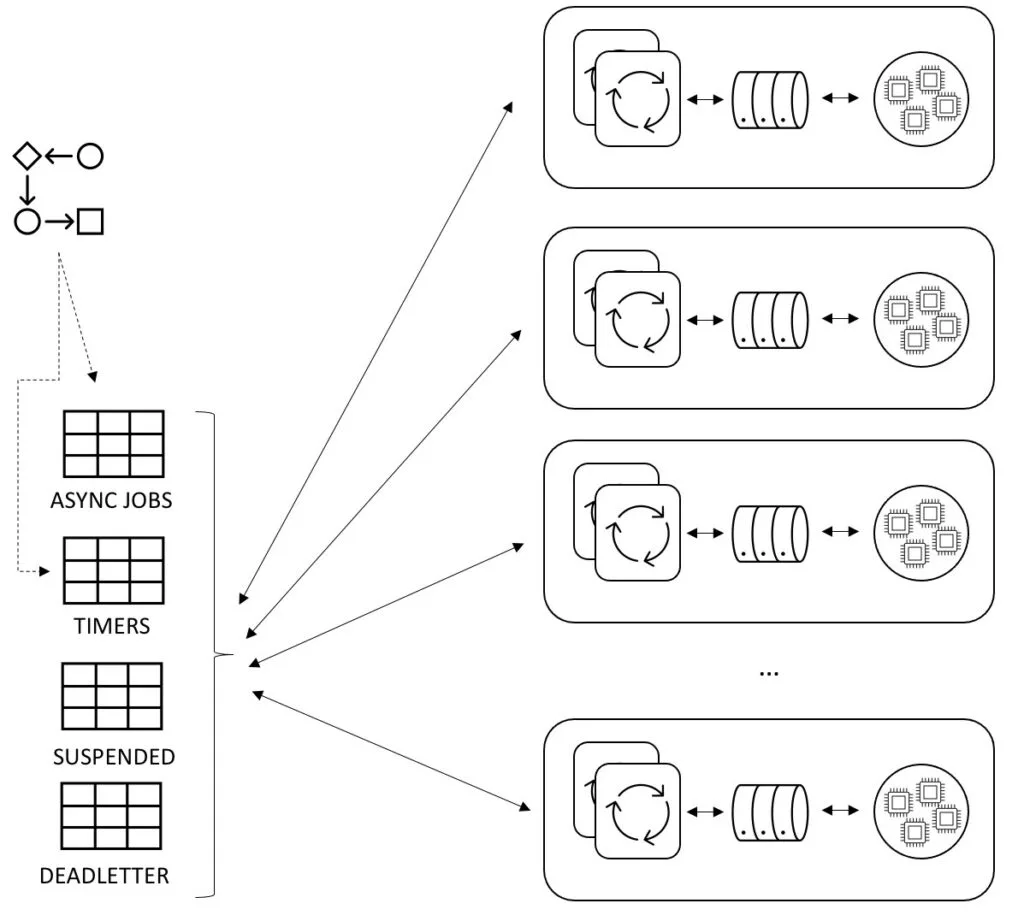
The architecture of the second generation of the Async Executor served the needs of Flowable users for many years, including demanding workloads. The third generation was not about a re-architecting the design, but refactoring the Async Executor into a truly reusable, independent component.
This was driven by the need for ‘asynchronous history’ and the need for a solid foundation for indexing data into Elasticsearch in the Flowable enterprise products. Explaining those topics would lead us too far here, but in summary the Async Executor was chosen as a performant way to move process and case data in the background to make the runtime database transactions more efficient.
More technical details about asynchronous history can be found here and on this blog.
Second to this was the proliferation of engines in the Flowable open-source project and enterprise products. Originally, Flowable was about BPMN execution only. However, this changed tremendously in those years, with the addition of many new engines, both in the open-source project as in the enterprise products. Some of these engines (most importantly, the CMMN engine, but also others, such as the content engine) had a need similar to the process engine for timers or asynchronous tasks.
As such, the Async Executor was refactored to be easily included into any engine. In this period, Spring Boot became ubiquitous, meaning it also became important to be able to hook into the low-level mechanisms of such environments (for example, directly using the default configured TaskExecutor from Spring Boot). Major refactorings were done and the Async Executor even got its own set of isolated services and Maven modules.
The end result was what we deem the third generation: a reusable, independent component that was now used for multiple and varied use cases in the Flowable open-source engines and enterprise products.
The third generation of the Async Executor evolved together with the increasing demands for the Flowable products. We kept improving and tweaking it, up to the point where we hit the next architectural bottleneck.
The first hurdle when trying to optimize an existing system is to know exactly where the bottlenecks are. As with any kind of engineering effort, the first goal is then to gather data and metrics. From our open-source community as well as from customers, we had gathered that the number of optimistic locking exceptions goes up when there are lots (hundreds of thousands) jobs in the database. Optimistic locking exceptions are not a problem in themselves, in fact, they are a sign of a normal working system and are to be expected. Instances will compete to acquire jobs. Some instances will acquire, and some won’t, which leads to optimistic locking exceptions in the logs.
However, if the trend of optimistic locking exception occurrences goes up and the number of jobs in the database doesn’t go down or even grows, that is a sure sign of a bottleneck. Using the benchmark project that we described in the previous part, we ran many experiments and prototypes while we hooked up a profiler. Sometimes, these implementations did not lead to better results, yet they gave insights into the way the various components of a realistic setup interact with each other.
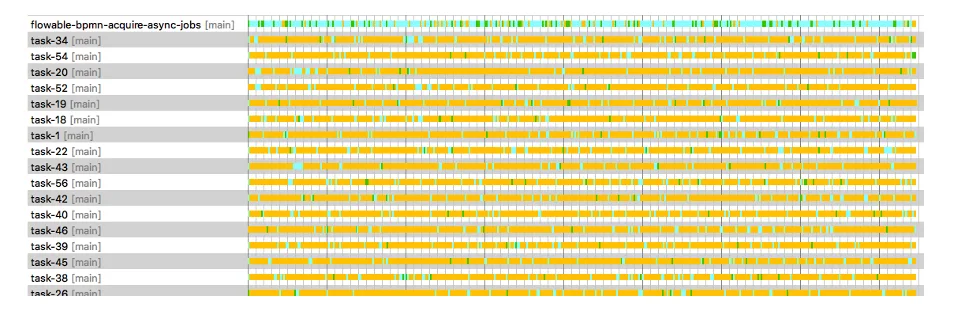
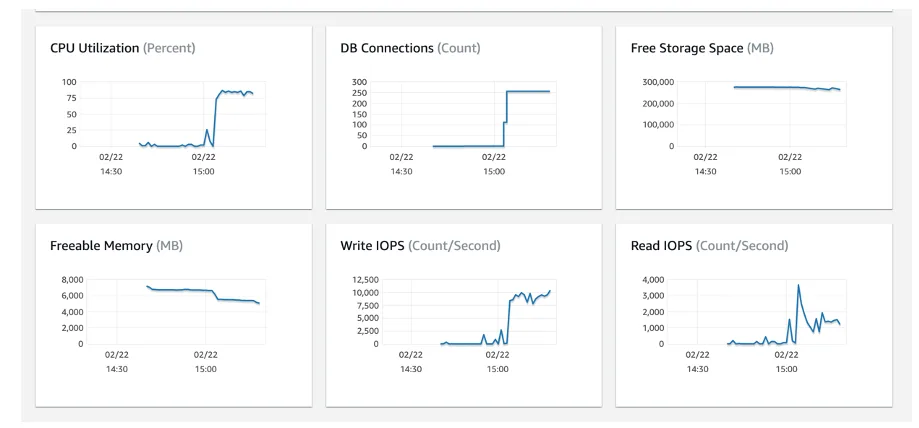
In the first rounds of experiments, one pattern became clear quickly: when ‘overloading’ the Async Executor with hundred thousands of jobs that need to be executed at the same time, the acquisition thread can’t serve the execution threads immediately when having a large number of Async Executor instances. We tried out various permutations of many settings we discussed in part 2: higher acquire sizes, tweaking the queue size, and so on. But the pattern remained, even though we found small improvements along the way. In the most optimal settings we tried, we could push it to 1200-1500 jobs / second (on similar hardware as in the benchmark post). This is visible in the following picture of the profiler (yellow means waiting):
When running the tests, the database server was close to being fully utilized, which is not something you’d want to see:
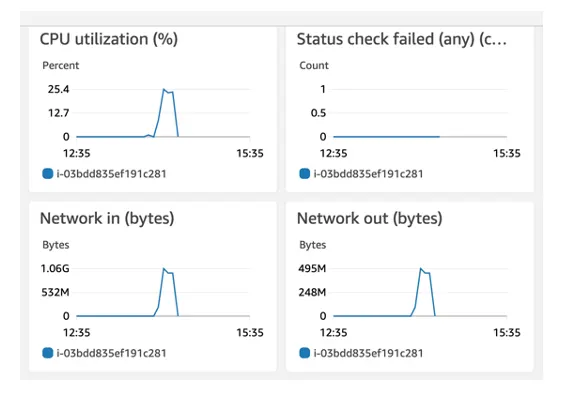
The servers running the Flowable Async Executor on the other hand were only used for a quarter of their CPU power:
One thing we did additionally see is that the number of optimistic locking exceptions increased linearly when adding more Async Executor instances. Again, this isn’t a problem as that’s how the third generation was supposed to work. In some cases, there would also be a deadlock exception happening, which was in fact an optimistic lock in disguise. As this topic has come up a few times in the forum, it’s worthwhile mentioning the following:
The term ‘deadlock’ is not a good word here. What happens is that database internally keeps locks on rows, when multiple transactions concurrently are executing. This is how ACID is guaranteed. However, when there are too many rowlocks (that number is configurable for most databases), the database kills one transaction randomly, in the hopes that the lower pressure will help the other transactions. When that happens, a deadlock exception is thrown on certain databases. Technically, however, this is not really a deadlock situation as with enough time the database could have been able to resolve it. There’s not the classic stand-off happening. However, many databases work with these time-locks to guarantee acceptable times.
One conclusion that became apparent when analyzing the data was that table concurrency is the bottleneck. The fact that the database was spending lots of CPU, combined with the many (ignorable) exceptions indicated that the database wasn’t able to cope with lots of concurrent queries and changes. The acquire phase was especially hit by this. Tweaking the acquire page size and queue size fixed it to a certain extent, but not as much as we had assumed.
We had seen this pattern before: when we went from the first to the second generation of the Async Executor, when the tables were split as a result. As the pressure on the single table increased, the throughput decreased. Splitting the table into four different tables reduced that pressure back in the day. We concluded we needed to find a way to lower the pressure on the tables.
The classic solution when confronted with competing concurrent consumers of the same data is to shard the data. In this context, sharding means that every job would get a sharding key and that the queries incorporate this sharding key when acquiring jobs. A shard is then effectively one subset of the total of data, specific for that sharding key. We did many other prototypes too, but it’s worthwhile explicitly looking at sharding, as it’s something that is a natural reaction to the problem stated above.
The idea: give each Async Executor one unique sharding key and partition the job data, one key for each instance. We used the category field for storing the sharding key, which already existed (and added an index):
Divide the 1 million jobs into 4 different sets, each with a category. This meant that there were 250K jobs with category A, 250K with category B, 250K with category C and 250K with category D.
Adapt the acquire queries to take into account the category, which was hardcoded on each instance.
Have one Async Executor instance for each set, four in this case.
The results of this experiment were disappointing. While this approach did lead to a slightly higher throughput when adding more instances, it was only a margin of 10-20% per instance, and getting lower with each instance. On the positive side, this approach had no optimistic locking exceptions nor any deadlocks happening. So, we knew we were on the right track to zoom in on the acquire logic.
Another downside of the sharding approach is that it would require picking a sharding key on job creation. This could be done round-robin for example, but it would mean that each Flowable instance should be aware of what other nodes were currently online and which keys were in use. Secondly, in case an instance went down, the existing jobs needed to be rebalanced to other sharding keys. Both these problems would require quite some complex changes. And, as a rule in software engineering, complex algorithms tend to lead to complex bugs. This fact, combined with the performance numbers led us to decide to keep this idea prototypical and not continue investing in this path.
It did highlight one thing to us: we were on the right track with trying to lower contention on the job tables. The sharding did make the queries simpler and avoid database row locks significantly, yet it seemed the amount of work on the same table was simply too much.
We experimented with various solutions and in the end decided for what we now call the Global Acquire Lock strategy.
Instead of having the Async Executors compete with each other for a set of jobs, each acquire thread first needs to get access of a global lock, before it can acquire those jobs. If the lock is currently held by another Async Executor, the acquiring backs off for a short time. The result is that in this setup, only one Async Executor is ever acquiring. The biggest benefit is that now the acquisition logic can be seriously optimized, because it doesn’t need to take into account that other instances could be trying to lock at the same time. The side-effect is that locking can now happen in bulk, without having to resort to optimistic locking as usual. It also means that far fewer queries actually get through to the job tables.
While it seems counter-intuitive (after all, we’re introducing some sorts of ‘gatekeeping’) this speeds up things, and does so tremendously (as seen in our benchmarks), because:
Even though only one node ever is acquiring jobs, the acquisition itself is much faster than before due to being able to do operations in bulk.
Lowering contention on the database tables actually makes the acquire query return faster as the table has to do less processing of concurrent requests.
Large pages can now be acquired without interference, which was a problem before. This makes sure that the executor threads have enough work. So, even if the acquire rate is lower, the amount of work fetched in one go is higher, thus making sure the threads are never starved for work. That is also why the default settings have now changed to pick up more jobs in one cycle.
Another side-effect is that the ‘heavy’ operation of transforming a timer job into an async job can be split off into a separate threadpool. This speeds up timer throughput significantly.
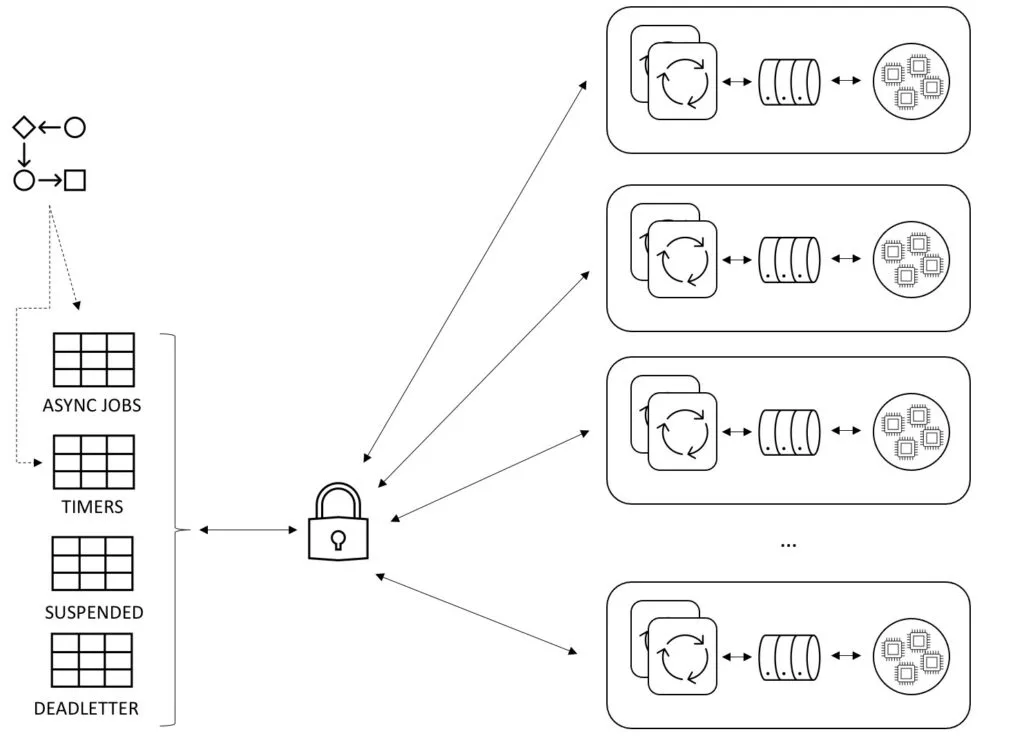
There are two additional reasons for going with this implementation.
The implementation is straightforward and doesn’t rely on more complex algorithms, such as leader-election (which we also considered). When it comes to concurrency, a straightforward implementation is easier to maintain, optimize and debug when problems arise.
All APIs can remain as they are, and this architecture is fully backward-compatible with the previous generations. No data migration is needed. In fact, it can be enabled or disabled with a flag (and even changed at runtime without a reboot). All of the other alternatives we analyzed did require a data migration.
Refactoring a complicated component and benchmarking it is always a complex matter. In this series, we hope that we have demonstrated that the new evolution of the Flowable Async Executor is a significant improvement on all versions that came before it. As shown, it is capable of handling thousands of jobs/timers per second. On top of that, it is done with both backward-compatibility in the APIs and the data.
The defaults that are shipped with Flowable open source (from version 6.7.0) and the Flowable enterprise products (from version 3.9.0) have been changed according to the findings in the various experiments we’ve conducted. Of course, settings can and should be tweaked depending on the actual system load. Hopefully, we’ve also demonstrated that the Flowable Async Executor is a flexible, performant and scalable component.
As happened with the previous generations of the Async Executor, we expect that the current architecture can be tweaked and polished further, based on user and customer use cases or new benchmarks. For example, one potential interesting angle is looking into dynamically sizing the acquire size of the various acquire threads or the execution threads. They could, for example, be based on a formula that takes into account the remaining queue capacity, the average execution time of the x last jobs, the pressure on the execution threads, and so on.
Another area could be investigating different lock implementations. For example, using a networked distributed solution for the global acquire lock instead of a database table.
Suffice to say, Flowable is always pushing the limits of its performance, without sacrificing the rich heritage and backward-compatibility that it adhered to for many years now.


Tools like ChatGPT can handle a variety of business tasks, automating nearly everything. And it’s true, GenAI really can do a wide range of tasks that humans do currently. Why not let business users work directly with AI then? And what about Agentic AI?

In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.
In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.