
Welcome to the third post of the series on the Flowable Async Executor. After having described the basic concepts in the first part and having looked at the various components with its configuration options in the second part of the series, it’s now time to answer the question that everyone is waiting for: how fast is it?
When talking about the performance of the Async Executor, the number one metric is the throughput of jobs/timers. Simply said: the higher number of jobs/timers executed within a given timeframe, the faster the process or case instances that use them will be able to continue.
The Async Executor continuously takes care of handling any new asynchronous job or timer that is due. To really test the system, we need to bring it into a state where a large number of jobs/timers are ‘ready to be processed’ and then let the Async Executor do its thing. To this end, we wrote a simple Spring Boot + Flowable application that does exactly that.
The source code can be found on Github and can be used if you’d like to reproduce and/or validate the results for yourself, or to compare against other implementations.
Of course, when it comes to asynchronous jobs and timers there is an important caveat: the time needed to “handle” them depends on the actual logic executed and what follows afterward in the BPMN or CMMN model. For example, if an asynchronous job is used to invoke a third party service that is slow, the job throughput will decrease because the threads will be busy waiting for the service to respond. Similarly, if after a timer or async task, one or more expensive steps follow that are not marked as async, they will all be executed within the same thread and also have a negative impact on throughput.
Taking this into account, the benchmark application generates three distinct types of data. In each setup, one million jobs of a particular type are generated before letting the Async Executor run. So, we have:
One million asynchronous jobs with a fixed execution time (for example, 100 milliseconds). This tests how close the Async Executor can come to the theoretical maximum, as the fixed time together with the size of the threadpool allows us to calculate the theoretical maximum;
One million timer jobs that are due to fire;
One million asynchronous jobs that don’t do anything (a no-op) and the next step in the BPMN model is a simple wait state. This provides the raw overhead of the Async Executor and will give an idea of the possible maximum throughput.
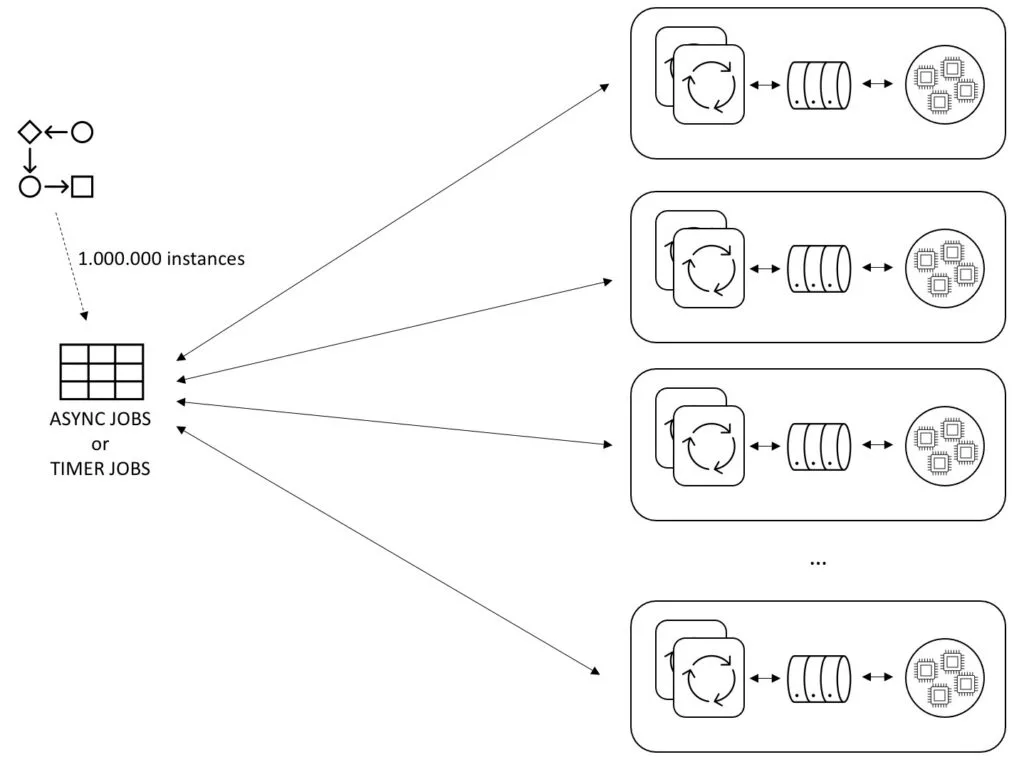
Again, note that this kind of setup tests both the acquisition of jobs and their execution. In a properly configured system, there shouldn’t be one million jobs lingering in the system, as it means the system wasn’t able to process them timely (at least for the async jobs), so the numbers here really are representing a worst-case-scenario.
The benchmark was executed on Amazon Web Services (AWS) using Elastic Cloud Compute (EC2) instances running Flowable with an Amazon Relational Database Service (RDS) database.
The EC2 Instances had the following configuration:
Operating System: Ubuntu 2020.04 LTS
Flowable engine: 6.7.0-SNAPSHOT
Instance type: C5.2xlarge (8VCPUs / 16 GiB ram)
JDK: version 11.0.10 (AdoptOpenJDK)
For RDS, we used the following PostgreSQL setup:
Version: Postgres 13.1-R1
Instance type: db.m6g.8xlarge (32vCPUs, 128gb RAM)
Provisioned IOPS: 30.000
Yes, this is significant compute power for the database as we didn’t want it to be a bottleneck.
We also ran the benchmark on Oracle RDS, but the Oracle license prohibits publicizing benchmarks.
The first benchmark we’ll look at is where all one million jobs (in a start -> async job -> wait state -> end BPMN model) have a fixed execution time of 100 milliseconds. This means that every thread of the threadpool will be blocked for 100 milliseconds, which is a long time for a modern CPU.
The results:
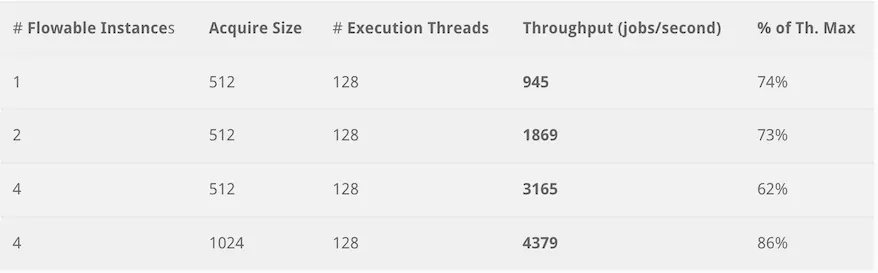
If the concepts of acquire size or threads don’t mean anything to you, please have a look at the previous post where we described these in detail. In this setup, we also used a queue size of 8192. We’re using a threadpool with 128 threads. On modern hardware and operating systems, with enough opportunities for I/O, this is typically not a problem.
Getting well over 4k jobs/second is a fantastic result. Well, actually, we need to say over 4k jobs that move a process instance forward at the same time, because the effect of executing the job is that the process instance state progresses. Simply said: the throughput number is the job execution time plus continuing the process instance (which also means additional database calls!).
It’s also clear that adding more Flowable Async Executor instances improves throughput and scalability, which is exactly what we assumed the Global Acquire Lock implementation would bring us. Also interesting is that changing the acquire size (how many jobs are fetching in one network call) improves throughput drastically here. This is of course dependent on your actual use case, but here it clearly is beneficial.
The last column is also an important one here: it compares the theoretical maximum (number of instances x 10 per second, as we’re using a fixed 100 ms time x number of threads). In the previous architecture, this number deteriorated quickly when adding more instances. In the new architecture, we can see this stays consistent and even rises to 82% when we tweak the acquire size. 82% of the theoretical maximum is an awesome result, as you need to take into account that there are also database response times and network delays included here.
This proves that the Global Acquire Lock strategy is excellent for distributing the load across multiple Flowable instances.
In the second benchmark, one million timers were generated (using a start -> task with timer -> task -> end process).
The results:
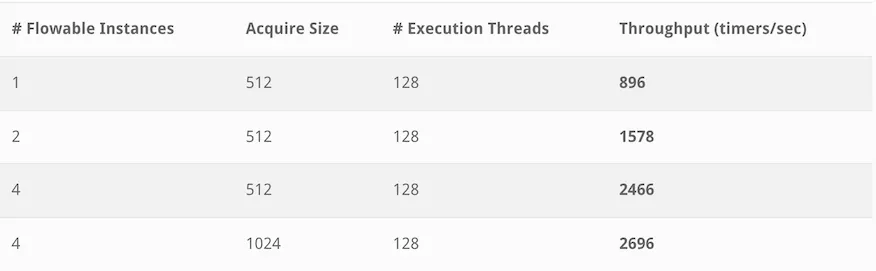
We see that the Async Executor in the best setup processes over 2.5k timers per second. Timers are more complex to handle than asynchronous jobs, so we expected them to be slower. Yet, over 2.5k timers each second is quite something. If we’d express the best result in throughput per hour, we’re effectively talking about close to 10 million timers per hour (9.7M to be exact).
In the last benchmark, we wanted to look at what happens when the job executes as fast as possible by having a no-op operation as job logic (not 100% true, the job logic executes a simple expression that simply does ${true}, so still means the expression is parsed and executed). This effectively benchmarks the overhead of the Async Executor, meaning that it will measure how well the acquisition and execution performs.
Of crucial importance here, is to validate that the steady stream of jobs moving through the whole chain of components never wavers. In the first benchmark this was easier because the execution time of 100 milliseconds gave more leeway to the acquisition and internal queue to be filled. With a no-op job, the Async Executor will need to work hard to constantly acquire new work and keep the queue nicely filled so that the threads are never starved.
Let’s have a look at the results:
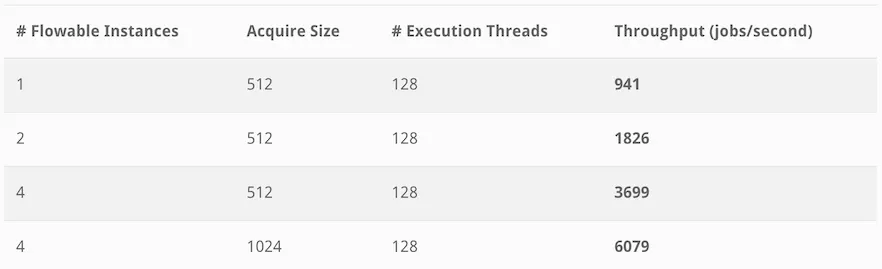
Comparing the results with the first benchmark, we can see that the first two rows are in the same ballpark. This could mean we were hitting a limit of the hardware in combination with the particular settings used. This would also explain why the third row result is about four times the result of the first row: the settings are the same except for the number of Flowable instances. It looks like, in this case, we could speed up things by fetching more jobs as most likely some threads were getting starved.
And that’s exactly what the fourth row proves: when doubling the acquire size, we see a significant increase in throughput. A whopping result of over 6k jobs/second.
Could this be made faster? Most likely, yes. Some quick tests showed that playing with settings, such as lowering the Global Acquire Lock wait time, increased the throughput (with a few hundreds/second). However, at that point, there is a danger of over-stressing the database, which is never a good idea.
Indeed, if we look at the CPU usage of the RDS instance when the benchmark was running in this setup, the CPU never went above 55%.
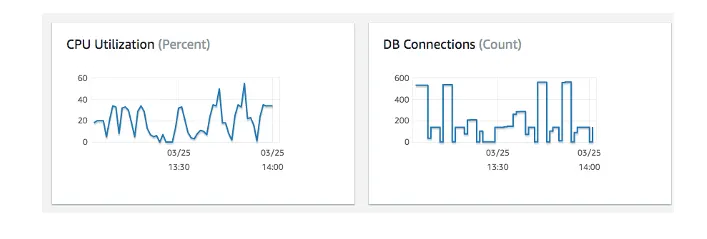
This does mean there still was room for optimization. However, to put the result above in perspective: we’re talking about 365k jobs / minute, almost 22 million jobs / hour and more than half a billion jobs per day.
Out of curiosity, we did the same benchmark with the global acquire lock disabled. This led to the following result:

This is about 1/6 of the throughput result compared to running with the Global Acquire Lock enabled. It is important to note that this is not the same Async Executor as it was in Flowable 6.6.0 because we’ve applied optimizations to all code involved, having learned a lot along the way. Consequently, even the “old” architecture is also getting a boost in the upcoming 6.7.0 engine release.
We’re very happy with the awesome throughput numbers – thousands of jobs or timers per second – being handled in these kinds of setups with the new Async Executor architecture. This validates our assumptions and experiments that the new architecture is a serious improvement on the previous implementation. As described in part 2, Flowable is very flexible when it comes to tweaking the various components of the Async Executor. It shows that understanding these configurations, and the underlying implications of the environment it’s running in, pays off big time.
The next generation of the Async Executor will be part of the upcoming 6.7.0 open source release. If you want to try it already today, you can get and build the source code from the main branch on Github. For enterprise customers, there’s already a supported version in the recent 3.9.0 version.
At this point, we have written down pretty much everything we wanted to tell the world. It goes without saying we’re extremely proud of the work and the results. We’re convinced that every Flowable user will be excited with these changes. After all, who doesn’t like faster processes and cases, or fewer servers needed for the same throughput ;-)?
There is one last post in this series coming up, though: how we came to this last iteration of the Async Executor. After all, when we look at the historical evolution of the Async Executor we can distinguish three generations of architecture, the Global Acquire Lock being the fourth one. And in every generation, we made a leap in understanding and pushed the capabilities of the Async Executor further.


Tools like ChatGPT can handle a variety of business tasks, automating nearly everything. And it’s true, GenAI really can do a wide range of tasks that humans do currently. Why not let business users work directly with AI then? And what about Agentic AI?

In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.
In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.