
Last week, more than thirty-one million process instances were started and completed on servers we spun up on AWS. The reason? To test and validate the various performance enhancements we’ve been adding in the past months to the Flowable engines in the upcoming 6.3.0 release.
We gathered an enormous amount of data. And we weren’t disappointed: most of the benchmarks at least show a double digit increase in throughput … and more!
Of course, as always when it comes to performance benchmarks, don’t give too much meaning to the absolute numbers. Benchmarks are always a snapshot in time and slight variations in hardware, setup or even time of day they are executed can alter the results. The main goal of the numbers and charts in this post is to highlight the relative differences between the Flowable versions that demonstrate the performance gains.
Varied changes, small and great, have been made in the 6.3.0 version. The following major refactorings have culminated in a significantly faster engine, with many of the improvements focused on avoiding or minimizing the amount of network roundtrips to the database server:
Dependent entity counting. During our profiling sessions it became clear that the cleanup of execution runtime structures often outweighs the time spent on the actual runtime behavior. The solution to this problem is spending more time at the insert or update time to calculate the number of dependent data entities instead of time spent at the cleanup phase. This feature has been in the engine for a while as an experimental option. However, it now has been expanded to more entity types and has been revised to also continue to work properly under high-concurrency scenarios.
Complex entity eager fetching. In real-life network topologies, it is often beneficial to exchange an extra network roundtrip for CPU cycles that compose a complex entity or related entities. Prime examples are the cmmn plan item runtime structure or bpmn executions. By getting more data than needed, subsequent calls to other parts of the complex data or related entities benefit from this short-lived caching. This feature has been added to the lowest data layer and is invisible for the layers above.
Cross-pollination of engine ideas. When thinking about a problem, it often helps to look at the obstacle from another angle. Implementing the CMMN engines has given us exactly that. Executing a CMMN case is quite different from executing a structured process. Some of the things we’ve learned by implementing this engine has given us a fresh look at how to optimize some parts of the BPMN engine.
Internal persistence. Many low-level classes related to persistence have been revised and optimized to be smarter about what is done when and only if absolutely needed.
The code for running the benchmark can be found here : https://github.com/flowable/flowable-benchmark/tree/8a804764115c476ea90f1826aab9161d27f35094/2018-03, so you can readily validate the results we’re claiming here.
In the results below, the first setup runs the benchmark on the same server as the database. In this case, the following default configuration was used
An AWS EC2 (Ubuntu) image of type c3.4xlarge (16 vCPUs, 30 Gib of RAM, SSD with provisioned IOPS)
On that same machine, a default (simply using apt-get install, no tweaks of configuration) Postgres 10.2 database
In the second setup, the database instance was not residing on the same server. The server machine running the benchmark was the same EC2 instance as the one above. The database had following characteristics:
AWS Aurora (compatible with MySQL 5.6) of type db.r3.4xlarge
All servers were in the same region (US-West).
Note that these servers have a lot of RAM, but in reality, not much was used. Flowable doesn’t use much memory and is very memory-efficient. For instance, the benchmark server never used more than 2 GB in the first setup and 1.5 GB in the second setup.
The setup we’ve used here is deliberately simple. There’s much more one can do by adding more servers, loadbalancers, and so on. When interpreting the results, do take in account there are various ways of getting even higher numbers.
The process definitions that were chosen are relatively simple, but selected for testing particular areas of the engine, so we can draw meaningful conclusions with regards to real-life process execution. For each of the process definitions, the start to end time has been measured. This means that not only the start of the process instance is taken in account, but also the querying of user tasks and completing them. As seen in the code from the benchmark project, the JVM was always warmed up adequately before starting measurement.
The benchmark is very simple: after the JVM warmup, a threadpool is created with X threads and Y Runnables (we’ve tested with X=[1..16] and Y=10000), which are executed by the threadpool. Each Runnable stores the execution time, which is then processed after all Runnables are completed calculate the average time and standard deviation. The total time for all Runnables is also measured and used for calculating the throughput. Such a Runnable typically contains the start of a process instance, querying for user tasks and completing them (see for example https://github.com/flowable/flowable-benchmark/blob/8a804764115c476ea90f1826aab9161d27f35094/2018-03/src/main/java/org/flowable/runnable/SubprocessesRunnable.java). Note that we’re not just measuring the start of a process instance, but the whole lifecycle from start to end, including querying.
You’ll notice in many (but not all) of the charts that the Flowable version 5 has a higher throughput than pre-6.3.0 versions. That’s exactly what we expected. The move to the version 6 architecture included a complete refactoring of the runtime data structures and, in most cases, there was more data persisted to represent the runtime structure. As a very simple example: a process instance is always a separate execution in version 6, while in version 5 it was recycled for pointing to activities as well.
More runtime data simply means more data inserts/updates/deletions. The reason why we chose to go with this architecture is because it enables a wide range of awesome features around dynamic behavior of processes (take a look at our BPMNext demo of last year https://www.youtube.com/watch?v=5qIw3JTw-mI or the more recent commits around the ‘ChangeStateBuilder’ that allow you to jump from any point in a process instance to any other point – more to come on that soon!). Those use cases cannot be implemented in a clean way on the version 5 architecture in such a way they are guaranteed to work for all process definitions you throw at it.
When the version 6 architecture was designed, we realized it would initially mean a slight dip in throughput performance. There’s no escaping that law when you have more data. However, we also knew that this architecture would be, over time, way more optimizable than the version 5 architecture. When your runtime structures are clean and follow clear algorithms, reasoning about optimizations becomes just much easier.
The article you’re reading right now is the result of exactly those optimizations. Of course, these didn’t fall out of thin air just by having a good architecture. They are, even more importantly, the result of many discussions, prototyping, profiling, cursing, swearing and simply hard work of the whole Flowable team.
Let’s have a look at the process definitions used in the benchmark one by one and the results for the various Flowable versions and configurations.
Description: The first “process definition” is hardly a process. It simply starts and ends immediately.
Why: Although not doing anything functional, this process definitions gives us a clear understanding of the overhead of calling out to the Flowable engine. This is the baseline, everything else will always be slower than this.
Let’s have a look at the results when running both the benchmark logic and the database on the same server:
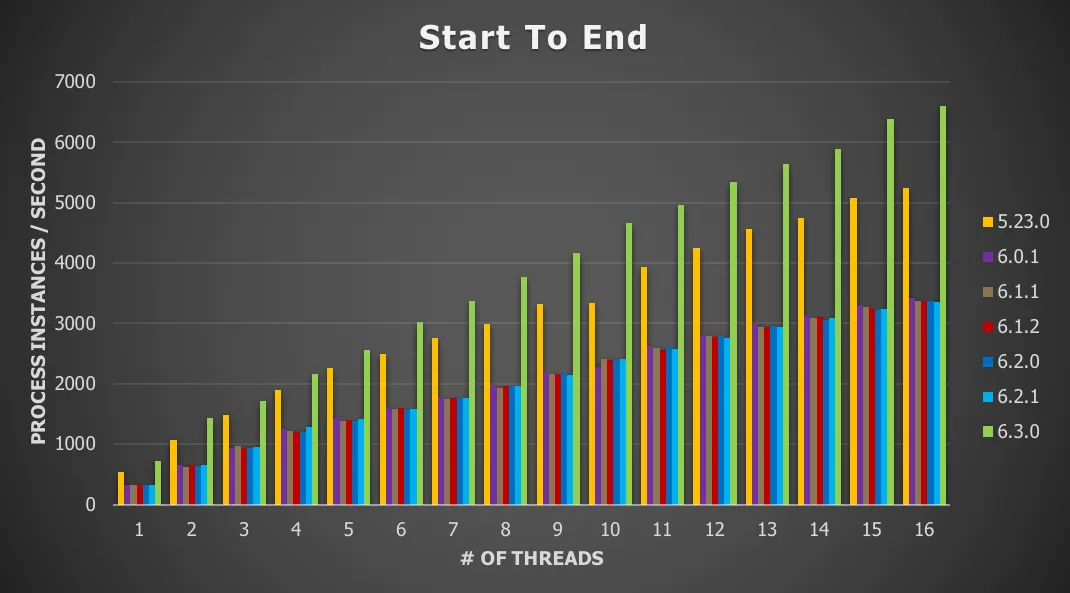
Chart 1: Single server with local database and history enabled
The y-axis shows the process instances per second. In this case, this means how many process instances are started, completed and the history stored in the database in one second. The x-axis shows the number of threads being used in the threadpool.
The following chart shows the best case (16 threads) only:
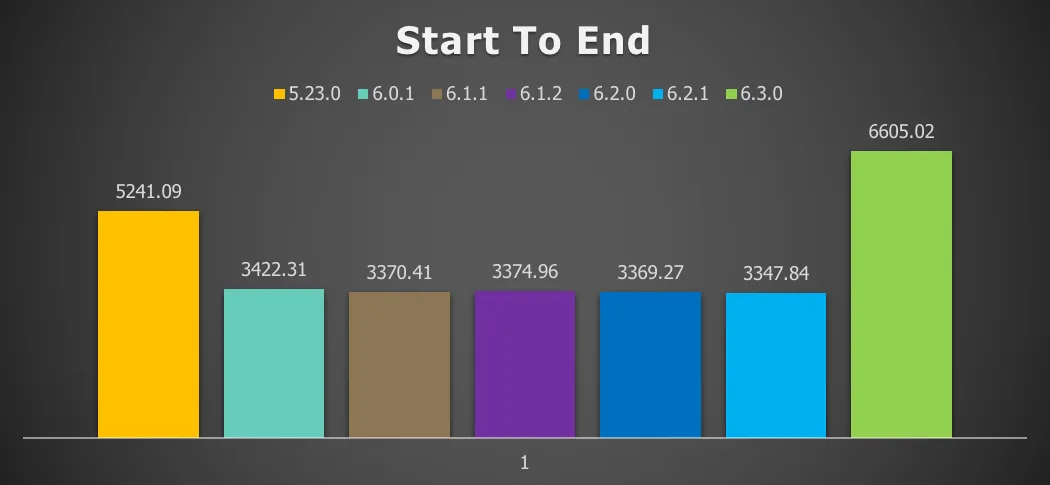
Chart 2: Single server with local database and history enabled at 16 threads
For this use case, we see a
26% throughput increase vs version 5
Almost a doubling of throughput vs pre-6.3.0 (read further below)
A few other observations from these charts:
The pattern predicted in the previous section (v5 version v6) is quite clear here. The reason is simple: the size of the runtime data structure is doubled, because in v5 there is only one execution entity and for v6 there are two. That is clearly visible in the difference between the version 5 and the pre-6.3.0 results.
However, the optimizations in version 6.3.0 avoid this penalty and actually improve on it. We’re going from 5241.09 process instances / second on version 5 to 6605 process instances/second on version 6.3.0.
Another observation is that Flowable has no problem scaling up and handling the concurrent workload. This is of course because the Flowable engine has been designed with high-concurrency in mind. There is a nice linear trend here when adding more threads. Of course, at some point there will be a physical limit on the CPU, but this sixteen-core machine hasn’t reached that point yet (we haven’t tested with more threads, which could tell us this tipping point).
Do note that when the throughput increases (the amount of process instances we can execute in one second), in general the average execution time per instance goes up as the CPU and IO systems are not constantly doing context switches. Do take in account we leave no breathing room for these systems, as we’re constantly bombarding them with work. In reality, there will be ample pauses. However, as clear from the chart, as the individual average execution time slightly rises, the throughput of the system globally increases. Let’s take, for example, the 6.3.0 average timing chart (we’ll only show this once, the pattern is the same for all the subsequent process definition benchmarks):
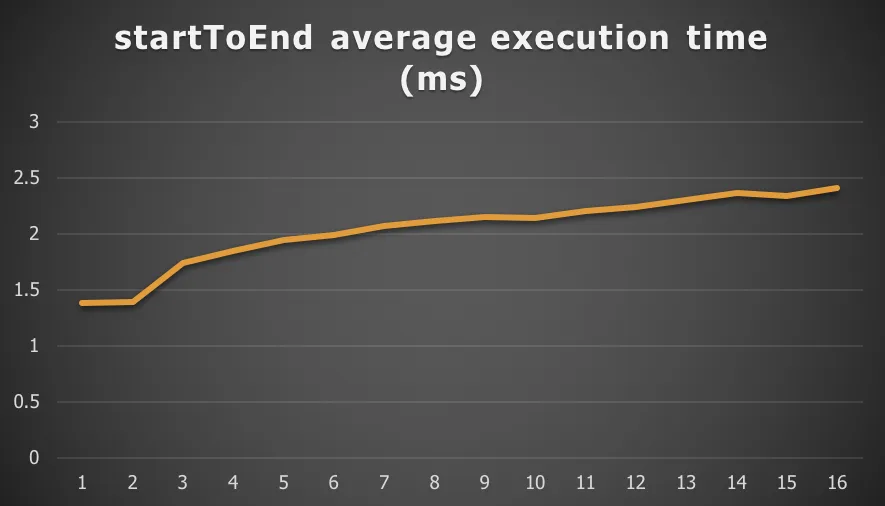
Chart 3: Average execution time per instance for 6.3.0
Also noteworthy here: we’re talking about 1.5 – 2.5 milliseconds for one process instance execution, which is very low.
In the numbers above, history data (process instance data, start and end times) are written to the historical data tables, using the default audit history level of Flowable. Let’s see what happens if we disable that:
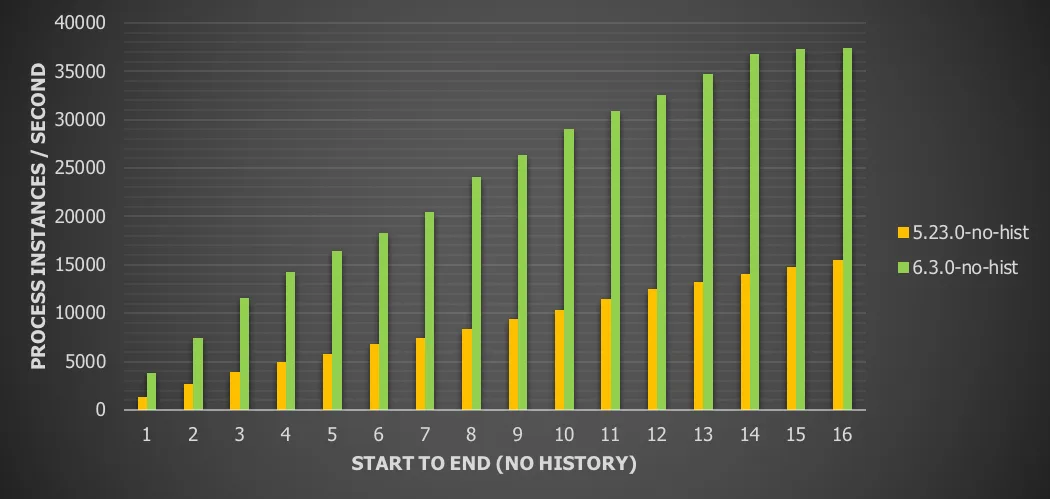
Chart 4: Single server with local database and history disabled
For this use case we see the throughput more than double (141%) vs version 5.
The results for pre-6.3.0 have been omitted for clarity. A similar pattern was found as above. It’s clear from this chart that, when running without history, the 6.3.0 version blows away 5.23.0. Also note the best result here (with 16 threads): 37453 process instances/second. Just to put that in perspective: that’s close to 135 million process instances / hour. Given the low execution time and the very high throughput, it’s safe to conclude from the benchmark of this simple process that the overhead of calling the Flowable engine is extremely low.
For the sake of getting clarity in the charts from this point on only the results from 6.2.1 and not any older 6.x version will be included. They are effectively equivalent in the resulting numbers.
The numbers above were all on a server where the database also resides. Once real network delays come into play by having the database on a separate server, the numbers obviously change:
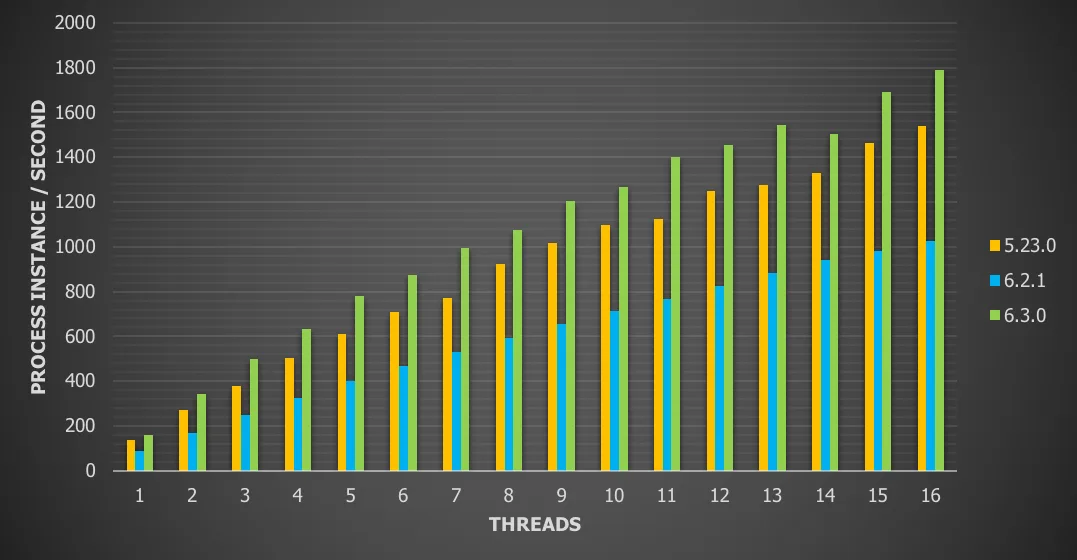
Chart 5: Single server with remote database and history enabled
For this use case we see a
16% throughput increase vs version 5
74% throughput increase vs version 6.x
One immediate observation is that by having to call a database over a network (even the probably quite well-designed network infrastructure in AWS) has an enormous impact (1/3 of the throughput compared to the first setup).
The non-history counterpart looks like this:
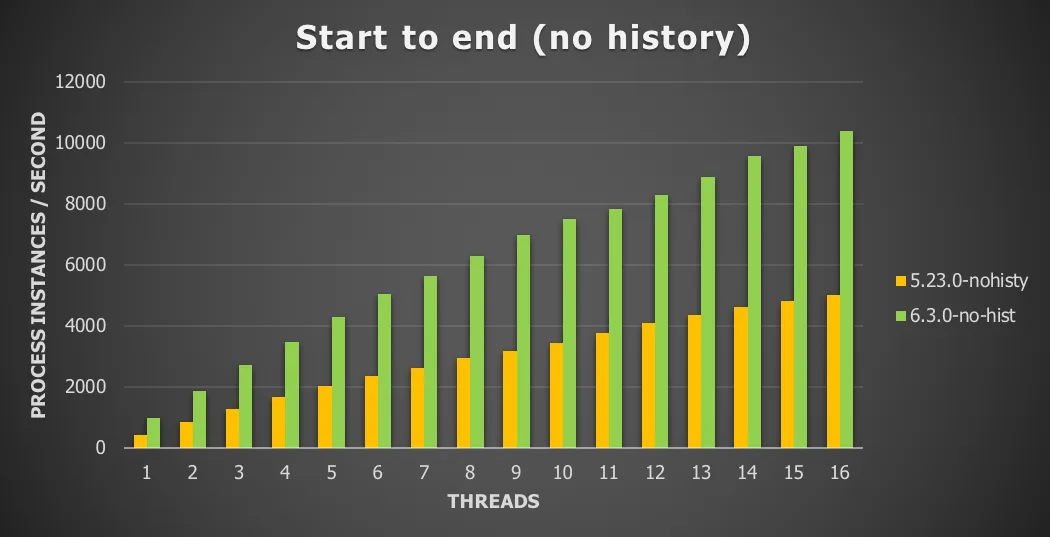
Chart 6: Single server with remote database and history disabled
For this use case we see a 106% increase in throughput vs version version 5.
The conclusion is the same: the 6.3.0 version is a significant improvement and the overhead of calling the engine is very low.
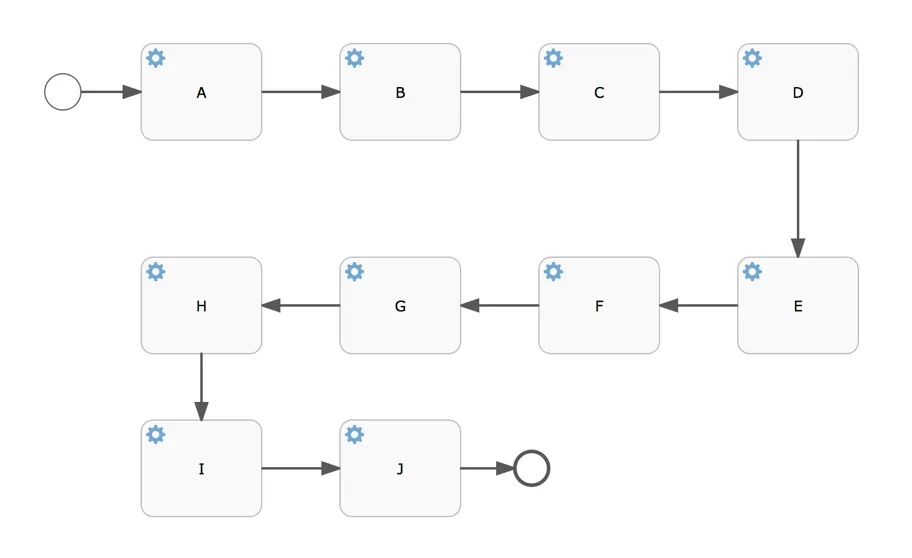
Description: This process definitions consists of ten service tasks in sequence. All service tasks are ‘no-op’ implementations (a class is defined and called, but there is no actual logic). Once a process instance is started, it will run to the end in one database transaction.
Why: This process definition will tell us about the overhead of the engine calling custom code and how well that scales when running in high-concurrency. Also, having ten tasks generates a nice bit of historical data which obviously impacts the throughput.
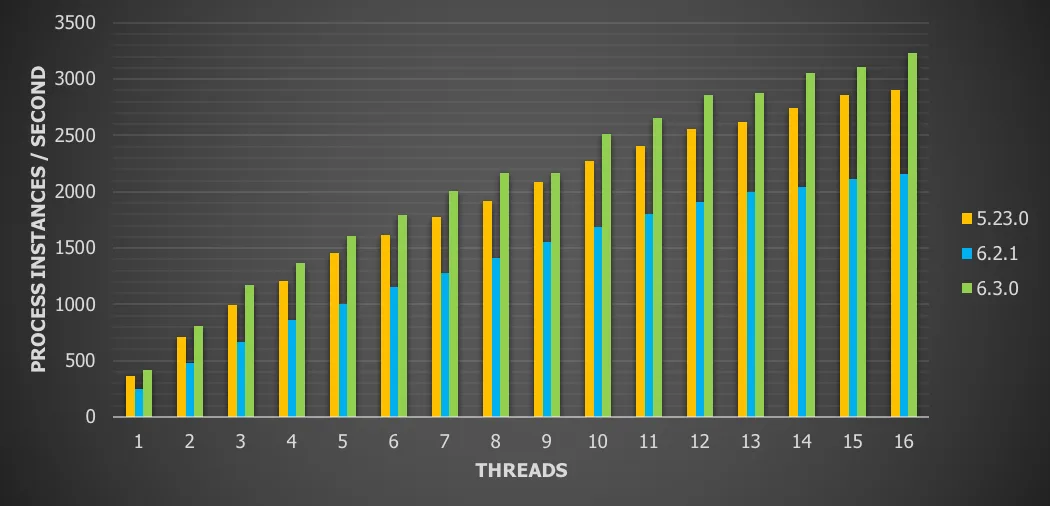
Chart 7: 10 sequential tasks with local database and history enabled
Or, only the best case:
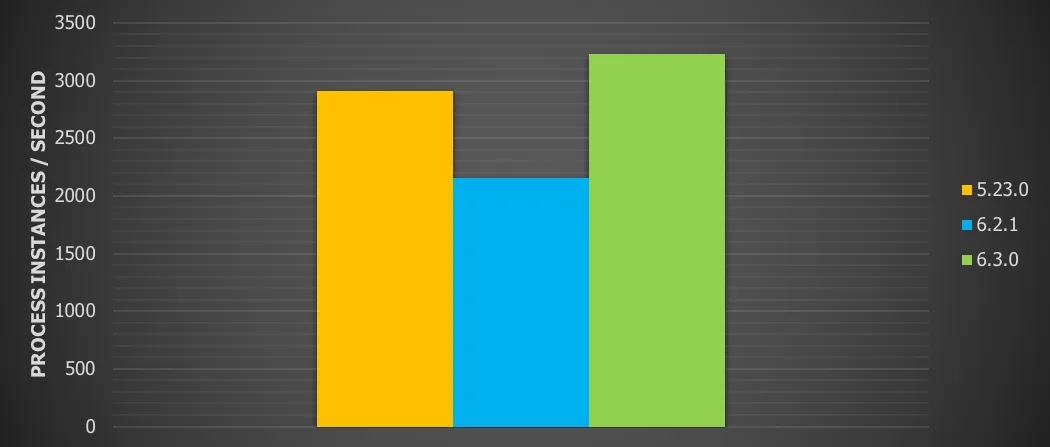
Chart 8: Ten sequential service tasks with local database with 16 threads and history enabled
For this use case we see a
11.2% throughput increase vs version 5
49.9 % throughput increase vs version 6.x
Note that having 10 sequential service tasks instead of nothing (previous process definition) divides the throughput by two. This is logical, as 10 service tasks do mean more history (one entry for each service task).
Without history, the numbers are much closer to the previous process definition (as there is not history data persistence, which is the biggest cost here).
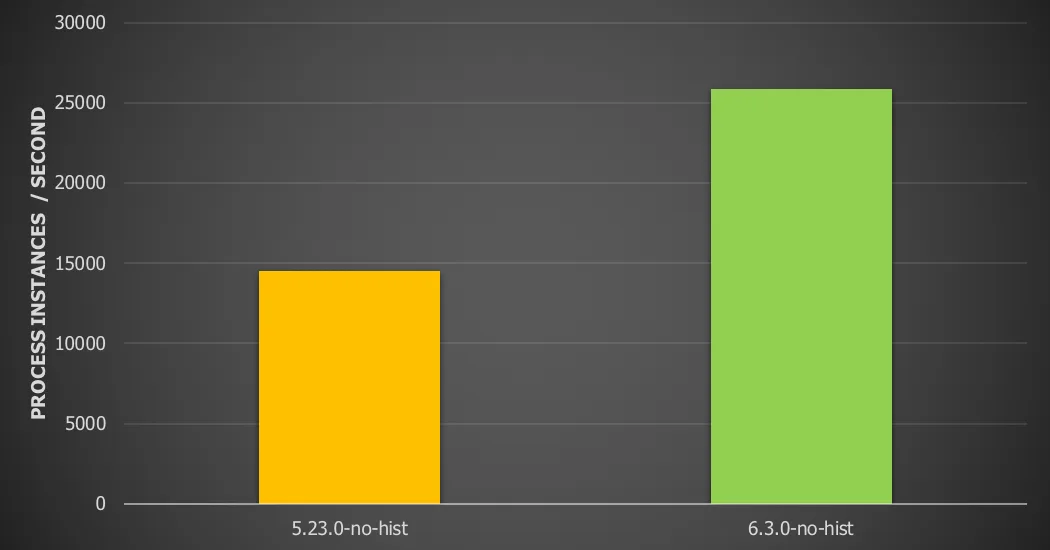
Chart 9: Ten sequential service tasks with local database with 16 threads and history disabled
For this use case we see a 78.8% throughput increase vs version 5.
The numbers for running on the AWS Aurora setup look as follows:
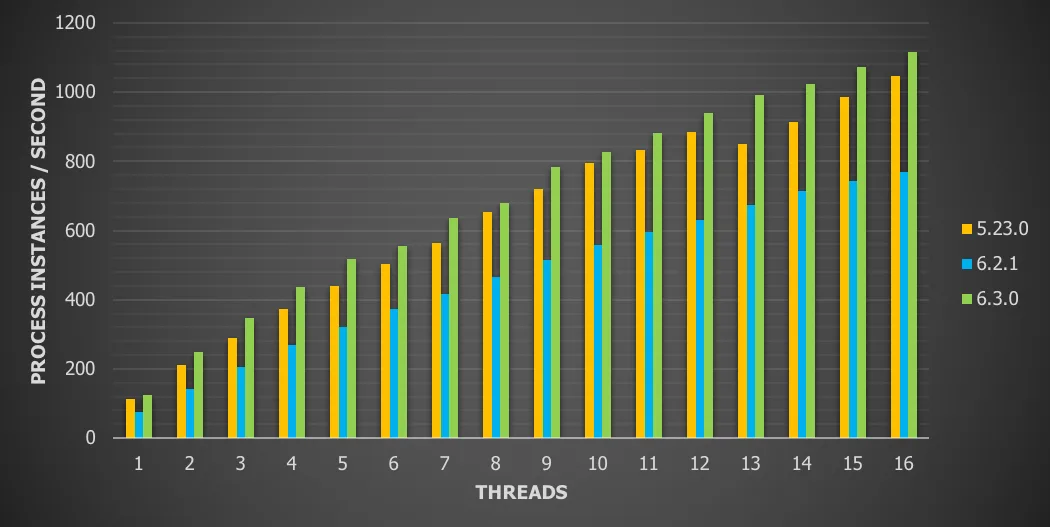
Chart 10: Ten sequential service tasks with remote database with 16 threads and history enabled
For this use case we see a
6.7% throughput increase vs version 5
45.5% throughput increase vs version 6.x
And the no-history counterpart:
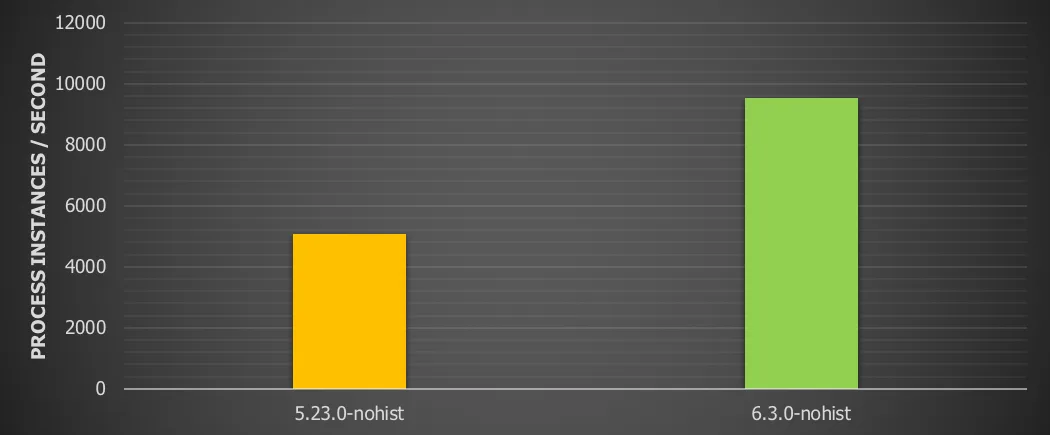
Chart 11: Ten sequential service tasks with remote database with 16 threads and history disabled
For this use case we see a 88.1% throughput increase vs version 5.
People that are interested in using Flowable for microservice orchestration (as history is less important there or it could be tweaked to not store the data that’s not useful) on AWS (or any other cloud environment) should take note of the results above. Close to 10000 process instances per second (9541 to be precise, which results in 34 million per hour!), each one executing 10 service tasks, can be achieved with this setup.
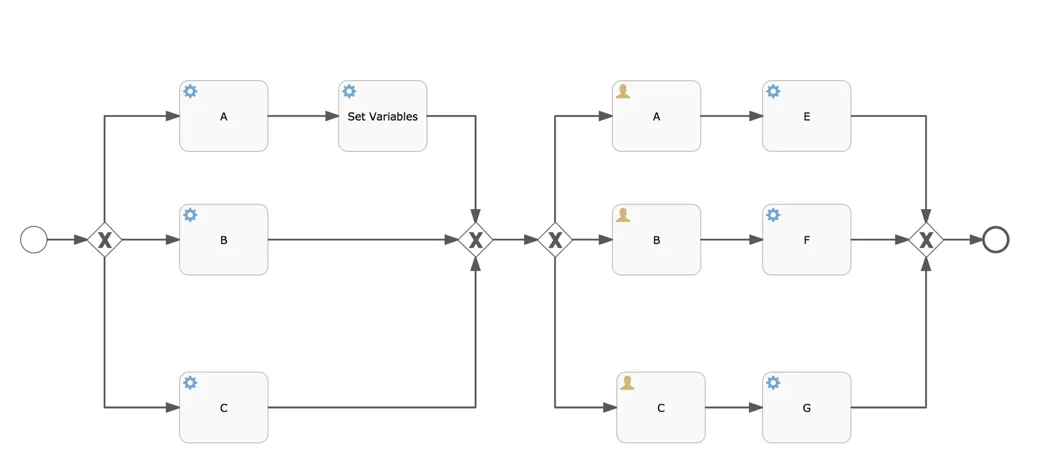
Description: This process definition doesn’t have a sequential path like the previous one, but splits the execution in the exclusive gateways. Furthermore, a process instance is started with twenty variables. In both exclusive gateways, the upper sequence flow is chosen. In the ‘Set variables’ service task, a custom service task is called that adds another thirty process variables. This means that when reaching task ‘A’, fifty variables (and fifty historic variables) will be persisted.
Why: The main thing about this process definition is that fifty variables will be persisted. We’ve seen users use process variables (and a lot of them) for many use cases, so this is an important one. Also, the benchmark includes the starting, task querying and task completing which gives us an insight into the performance cost of wait states in process definitions.
Let’s have a look at the results of the first setup:
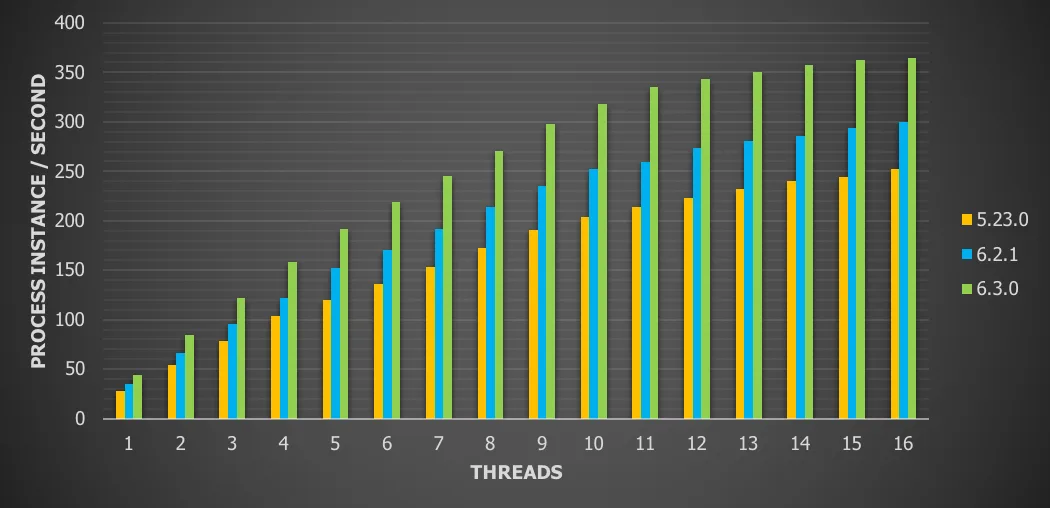
Chart 12: Many variables with local database and history enabled
For this use case we can see a
44.4% throughput increase vs version 5
21.5% throughput increase vs version 6.x
In the best case here, we’re pushing over 350 (550 without history) process instances with fifty variables, some exclusive gateways, a user task and task completion.
Again, take into account that the numbers here and for all following sections mean something else than the previous two process definitions. Here, whole lifecycles of start-task; query-task; and complete are benchmarked, not just the starting of the process instance!
Note that, contrary to the previous two process definitions, the results of the pre-6.3.0 versions are actually better than the 5.23.0 results. The reason is that we spent some time optimizing variable persistence in the 6.x branch a while ago, and this shows here.
On the second setup:
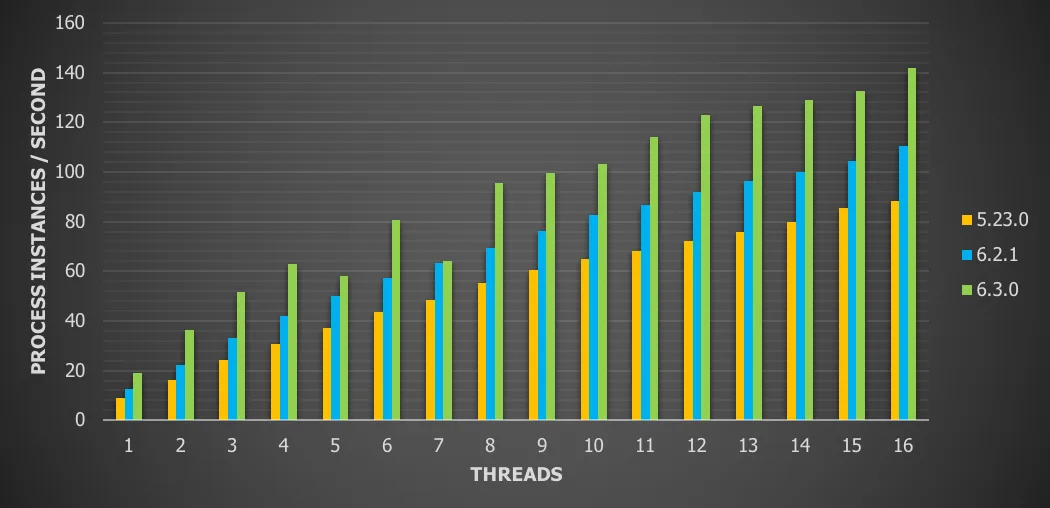
Chart 13: Many variables with remote database and history enabled
For this use case we can see a
60.9% throughput increase versus version 5
28.3% throughput increase version version 6.x
A similar pattern as before when running with real network delays, except it is now more than half of the throughput compared to one third.
The same conclusion as from the first setup can be drawn here: the recent 6.x versions and the 6.3.0 release significantly improve the throughput when working with process variables.
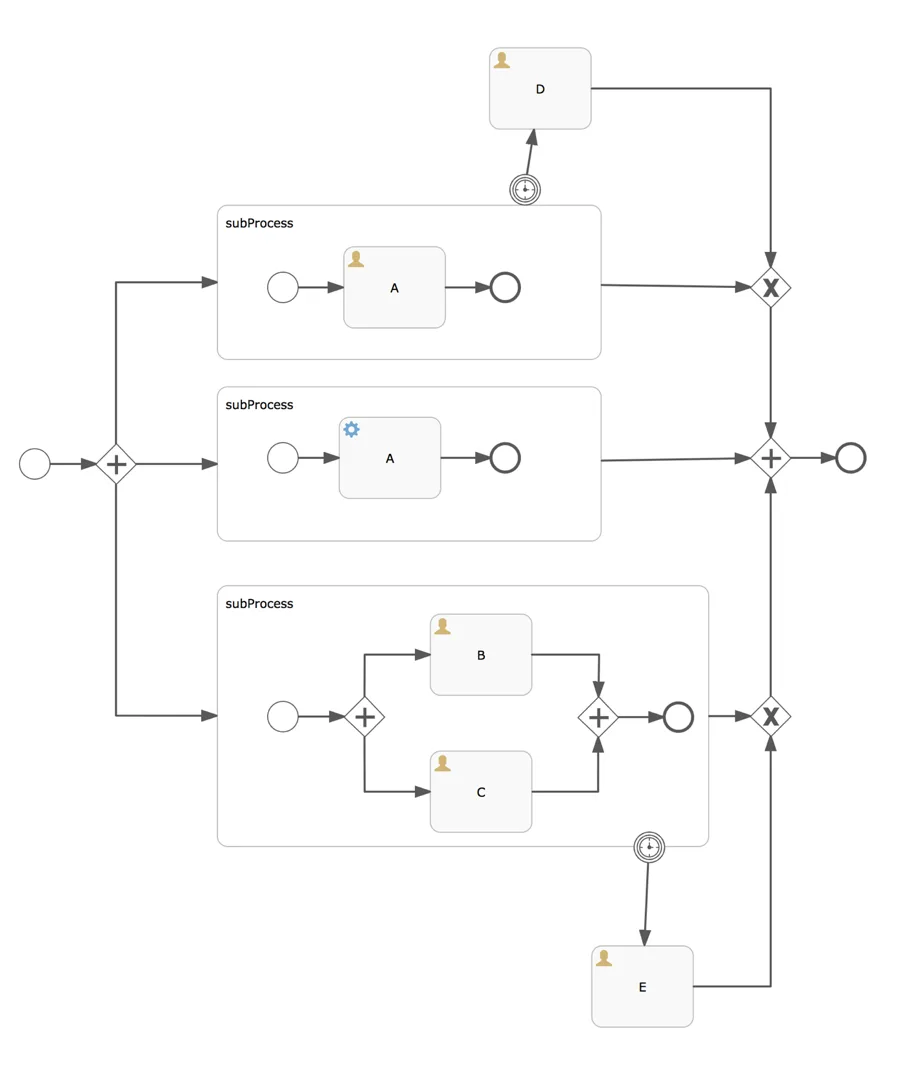
Description: This process definition tests the parallel behavior with a parallel gateway splitting into three subprocesses. One subprocess (the middle one) will go to the parallel merge immediately, the others have user tasks that will cause waiting (the lower subprocess splits up again in parallel). Both the upper and lower subprocesses have a timer boundary event. In the benchmark, a process instance is started, the tasks are queried and the three tasks are completed. This means that the subprocesses, boundary events and timers will have to be cleaned up after the last task completes.
Why: A process instance started from this process definition will have a non-trivial execution tree (the runtime data structure). This benchmark will give us insight in how well the engine handles splitting into parallel paths and merging again.
The results for the first setup and second setup show similar patterns:
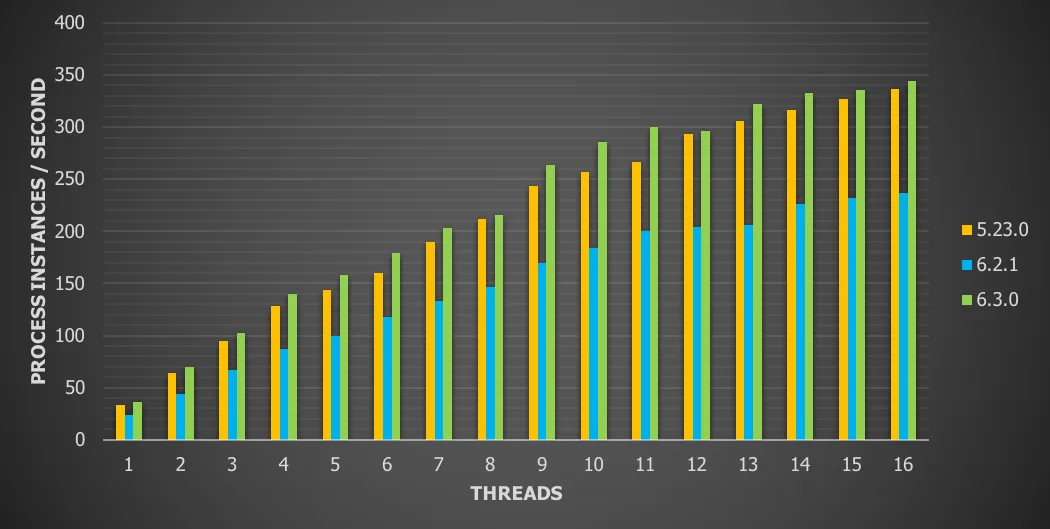
Chart 14: Parallel subprocesses with local database and history enabled
For this use case we see a
2.4% throughput increase versus version 5
45% throughput increase versus version 6.x
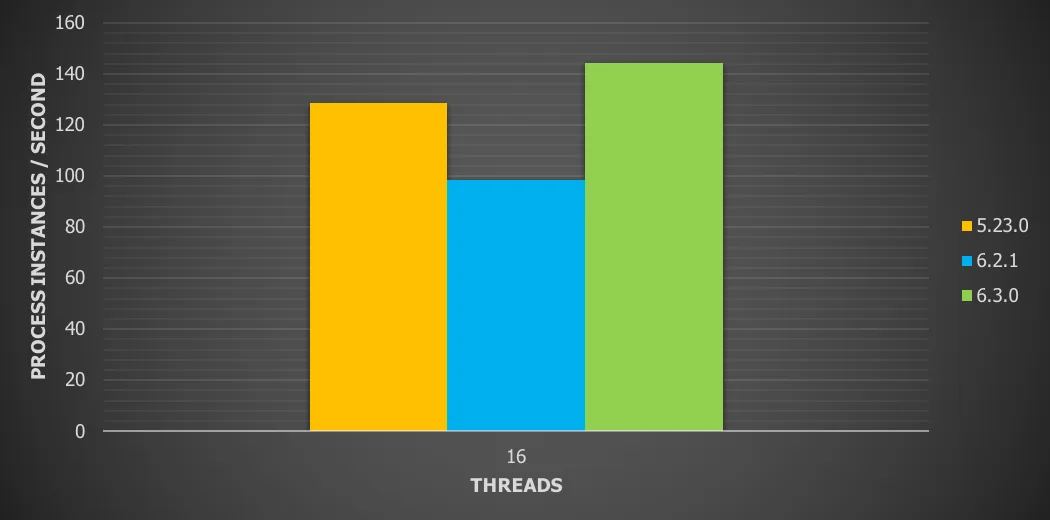
Chart 15: Parallel subprocesses with remote database and history enabled with 16 threads
For this use case we see a
12.4% throughput increase versus version 5
46.5% throughput increase versus version 6.x
Both show that the 6.3.0 is more performant when it comes to handling parallel processes, subprocesses and more complex execution trees. The difference with version 5 on a local database is not that big, as the CPU time spend building the execution tree in memory is actually more expensive than calling the database on the same machine. But when going to the real network setup, it’s clear that the investment is worth it as the difference becomes significant.
Also take in account that what is being measured here is actually the process instances start, querying for 3 tasks and completing each of them separately. Profiling showed us that actually a big chunck of the time was spent of the task query. So getting 144 of these cycles per second is very good.
When running without history, this pattern was less clear. Yet still 10 process instances could be executed more per second. I’ll take that any day ;-).
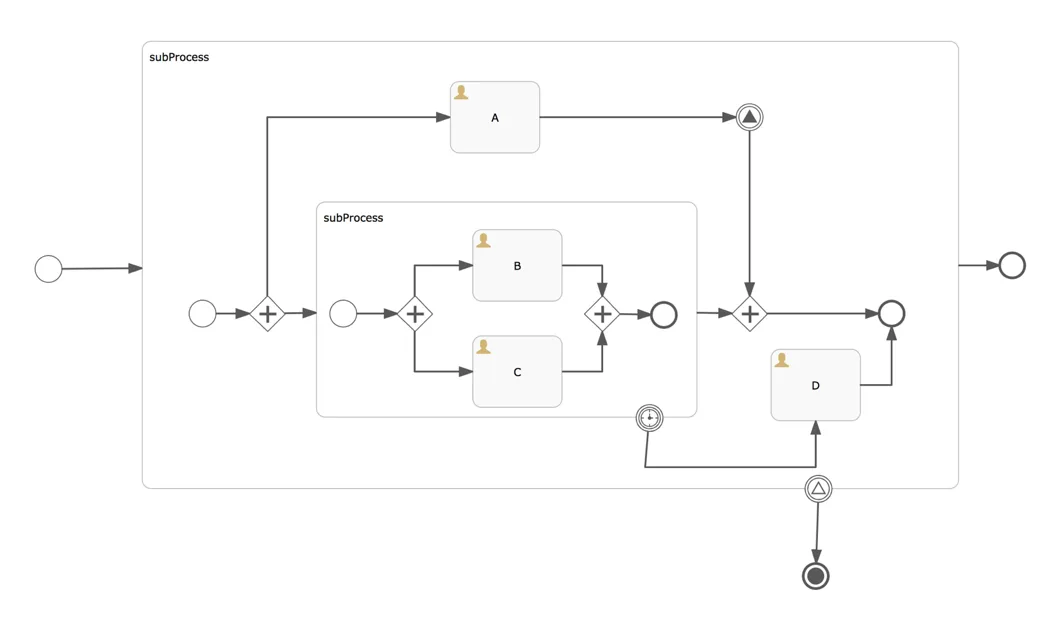
Description: This process definition contains an embedded subprocess with a signal boundary signal event. Inside the subprocess there are a few parallel things going on, a timer and an intermediary throwing timer event. The benchmark will start a process instance with 10 process variables and do a task query for task ‘A’. This will lead to the signal boundary being activated and the whole thing will be destroyed and the process will end.
Why: This process definition tells us about how the engine handles signals, but more importantly gives us insight into how the engine breaks down a non-trivial execution tree (subprocess with nested subprocess in parallel, with nested parallel stuff again, with a timer, etc.).
The results for the local database setup are shown below and show a significant increase when compared to the version 5 throughput.
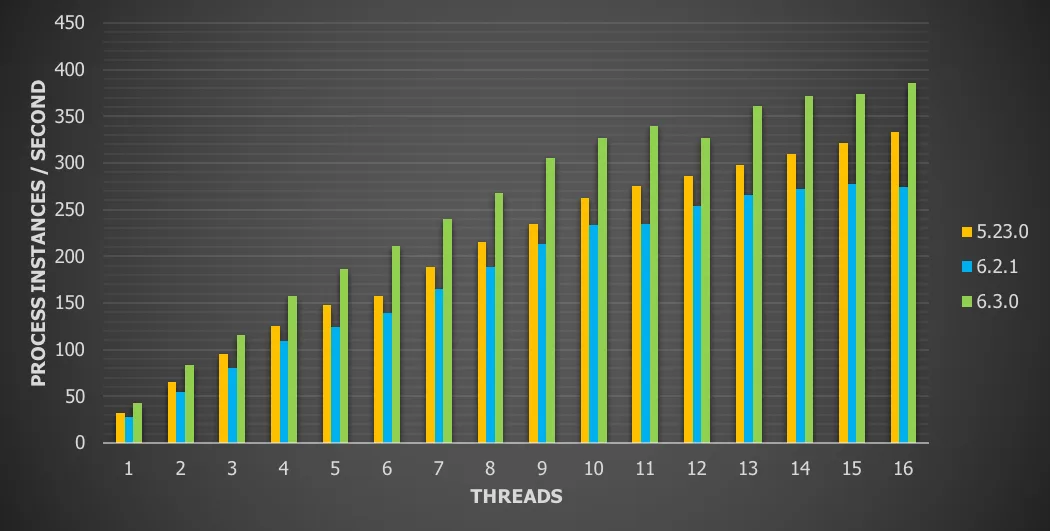
Chart 17: Terminate tasks with local database and history enabled
For this use case we see a
15.9% throughput increase vs version 5
40.9% throughput increase vs version 6.x
Now, when running with real network delays an interesting thing shows: the relative difference between version 5.23.0 and 6.3.0 becomes relatively larger. The explanation for this is that this benchmark really exercises the entity dependency optimization, which has a great impact on the amount of times we have to go over the network.
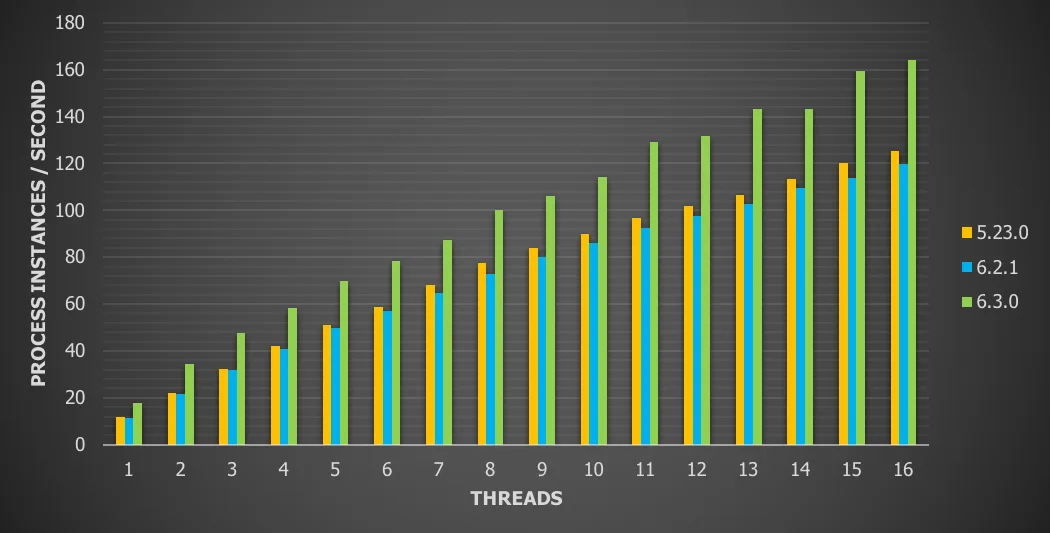
Chart 18: Terminate tasks with remote database and history enabled
For this use case we see a
31.8% throughput increase vs version 5
37.2% throughput increase vs version 6.x
In all of the results above we spoke about process instances per second, often in the thousands or hundreds per second like it was nothing. But let that sink in for a moment. Even our “worst” result of 141.73 instances / second means more than half a million process instances per hour, from start to end, including querying!
The process definitions we benchmarked were chosen for testing specific areas:
startToEnd: the overhead is extremely minimal. If we’re just invoking the engine, we got numbers up to 135 million process instances / hour. We’re pretty proud of that number.
allSequentialServiceTasks: when doing service orchestrations, Flowable has your back. The throughput (best case was 34 million process instances / hour) was very high while maintaining a high level of concurrency, certainly if you tweak the history settings (or add in asynchronous history, more on that in a next post).
manyVariables: variables are used everywhere and a lot. This benchmark clearly demonstrated the 6.3.0 is superior to any version before when it comes to handling variables.
parallelSubprocesses: this benchmark showed is that the 6.3.0 optimization that builds the execution tree in-memory pays off when having real network roundtrips.
terminateUserTasks: this benchmark showed that the optimizations around avoiding and minimizing the network roundtrips are working properly when a process instance is halted in the middle of its execution.
The general conclusion is easy: 6.3.0 is our fastest version ever (so far), Upgrading to the latest soon-to-be-released 6.3.0 will give you a noticeable performance boost -ranging from a few percent to potentially doubling the throughput- without any change to your code. The charts also demonstrated that the Flowable engine has no problem scaling concurrently. And yes, we do have some new ideas already where we can improve even more!
What if we told you these aren’t our best numbers yet … ?
Stay tuned for a next post where we’ll look into the benchmark results when using the asynchronous history feature!


Tools like ChatGPT can handle a variety of business tasks, automating nearly everything. And it’s true, GenAI really can do a wide range of tasks that humans do currently. Why not let business users work directly with AI then? And what about Agentic AI?

In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.
In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.