
Author: José Antonio Álvarez
Note: This post is a continuation of this one, as many readers have asked what happens when asynchronous jobs run out of retries.
After a job fails several times (depending on the configured number of retries [1]), the engine won’t execute it again. Instead, the job will be moved to a different table in the database called the dead letter table (ACT_RU_DEADLETTER_JOB). The dead letter is a common pattern in message passing systems.
Having all of them in a separate table helps finding the problematic jobs with a single and simple query. In addition to that, this partitioning of jobs improves the overall engine performance because failed jobs won’t have to be filtered out by queries from the async executor. Only Flowable 6 releases support this concept.
The big question is then what to do with the dead jobs. Flowable provides two ways of bringing them back to life: programmatically and manually via UI.
Programmatically: Flowable provides an API to reanimate jobs, see org.flowable.engine.ManagementService#moveDeadLetterJobToExecutableJob(JobId, retries). The result of the execution is that the Job is moved back to the table containing the running Jobs (ACT_RU_JOB) and the number of retries set to the parameter value.
Manually: There is a section in the Flowable Admin App that displays the current list of jobs. On the right hand side, the Job type filter has an option to show only dead letter jobs. Once this filter is applied, the list will now display the number of remaining retries (zero) and the Exception that caused the job to fail:
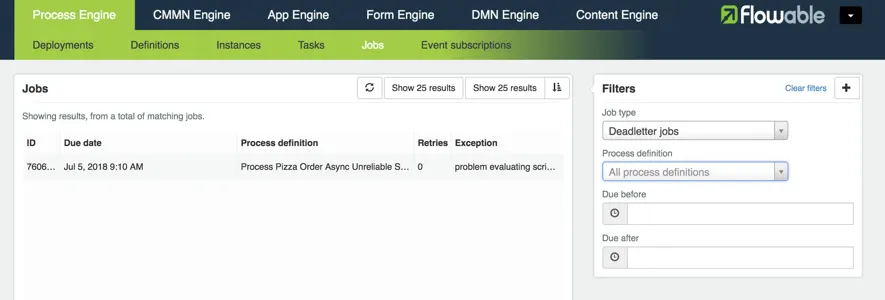
When clicking on an entry, additional information will be shown and, on the right-hand side, possible actions. The first action, ‘Move job’ will move the job out of the dead letter table, so it will be queued again for execution. The second option, ‘Delete job’ will delete it, but then the associated process will be stuck and will need to be cleaned up.
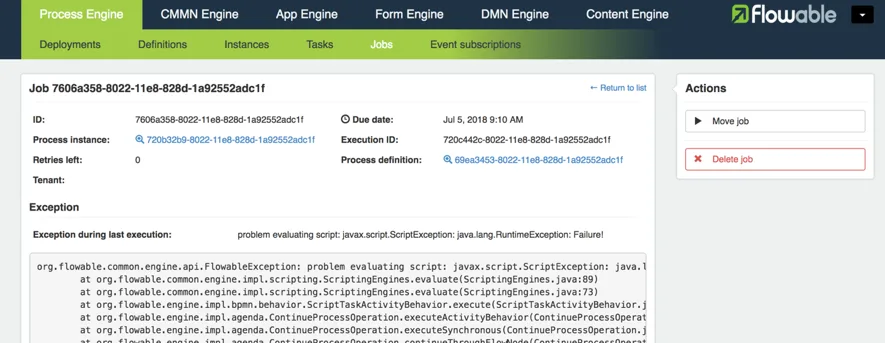
The most appropriate action to be taken is dependent on your use case and the nature of the exception. Flowable provides you the tools and infrastructure, but the error handling strategy is decided entirely by the requirements and the development team.
Some hints:
Failures in the communication, server down, unreliable network will throw easily recognizable exceptions: timeouts, network or I/O exceptions. In this case, triggering the Job again usually solves the issue, given the infrastructure is properly working again. A backend component could be written that periodically checks the dead letter jobs and, based on the exception type of a job, move it back to the regular job table.
ServiceTasks that call backend services whose implementation is buggy won’t succeed even if they’re retried multiple times. In this case, the bug has to be fixed first and then the job reactivated. If it was properly fixed, the process will normally continue its execution.
If the failed task is not critical, for instance a mail notification could not be sent but your Customer Care already called the client, the job could be deleted to avoid sending a redundant confirmation.
References:
[1] See documentation, parameter asyncExecutorNumberOfRetries.

Tools like ChatGPT can handle a variety of business tasks, automating nearly everything. And it’s true, GenAI really can do a wide range of tasks that humans do currently. Why not let business users work directly with AI then? And what about Agentic AI?

In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.
In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.
