
Last week, we published the performance benchmark results for the (upcoming) Flowable 6.3.0 release. The conclusion in that post is simple: the changes introduced in 6.3.0 make it the fastest version, compared to any previous version. In that post we also hinted at the fact that these weren’t the best results yet.
The way to achieve these better results is by using the “asynchronous history” feature of the Flowable engine. Let’s have a look briefly at what asynchronous history means and then dive into the results.
As mentioned in the previous post, the importance of the numbers here is their relative differences rather than absolute values. More specifically, what we showcase here is the difference between the best results from our previous benchmark post and running the exact same processes in the very same environment with asynchronous history enabled.
The ‘Asynchronous History’ feature is something we’ve mentioned in the past, but haven’t given too much spotlight yet. It was mentioned in the release notes of 6.1.0 and in the docs. It was also used for the Devoxx 2017 demo and is showcased in the examples.
The feature was born after a few profiling sessions that demonstrated a significant portion of time was spent processing the “historical” data (it may still be data for an active process, from steps already executed, not just the history of completed processes). The basic idea, as the name implies, is to process the history at a later point in time, asynchronously. Instead of flushing all to the database, the history data is stored unprocessed in the database. It’s possible to hook this into a message driven architecture (there are helper classes in the engine for integrating with message queues, check the links below). The engine also guarantees that this is all transactionally correct, even when using message queues (which is something often overlooked).
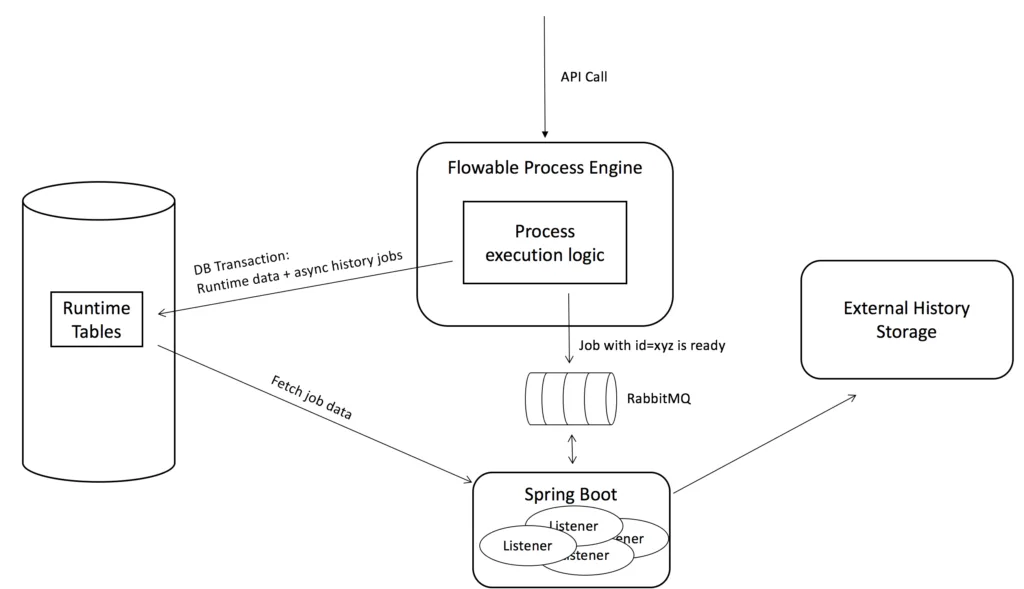
Example setup from the Flowable example (https://github.com/flowable/flowable-examples/tree/master/async-history/async-history-rabbitmq-cfg)
For a detailed explanation on asynchronous history and the implementation behind it, check https://github.com/flowable/flowable-examples/tree/master/async-history/async-history-default-cfg#description
It’s also designed to run easily with message queues out of the box. For more information, check out
The basic idea is that:
The history is processed asynchronously later, after the process instance has written its state to the database. The user gets control back faster, which results in faster user interfaces (or faster machine to machine communication if no user is involved).
Less network roundtrips, because historical data is combined. The previous performance benchmark demonstrated that having fewer network roundtrips generally led to a higher throughput.
It also means that historical data is not available immediately but with a slight delay when querying.
The same benchmark project as in the Flowable 6.3.0 performance benchmark was executed on the same set up of machines as used there on AWS, but now with asynchronous history enabled. On the left-hand side of the charts the ‘baseline result’ of 6.3.0 is shown. For this setup the ‘remote database’ setup scenario as described in the link above was benchmarked: this means an AWS Aurora instance with real network roundtrips. The ‘local database’ made less sense to run, as the purpose of asynchronous history is exaxctly to minimize network roundtrips and data transfer, which are less apparent in the local setup, and less realistic in real-world use.
Note that the numbers for the same version can slightly vary with results of the previous article. Even running on AWS with the exact same environment can give slightly different numbers, depending on the time of day, as we’ve found out. For a more elaborate description of the process definitions used in the benchmark, please read the previous benchmark blog post linked above.
Keep in mind that the left-hand side is the best result from the 6.3.0 benchmark … so if you were impressed by the performance gains there you are going to like this!
The first process definition was the simplest of them all: just a start event followed immediately by the end event:
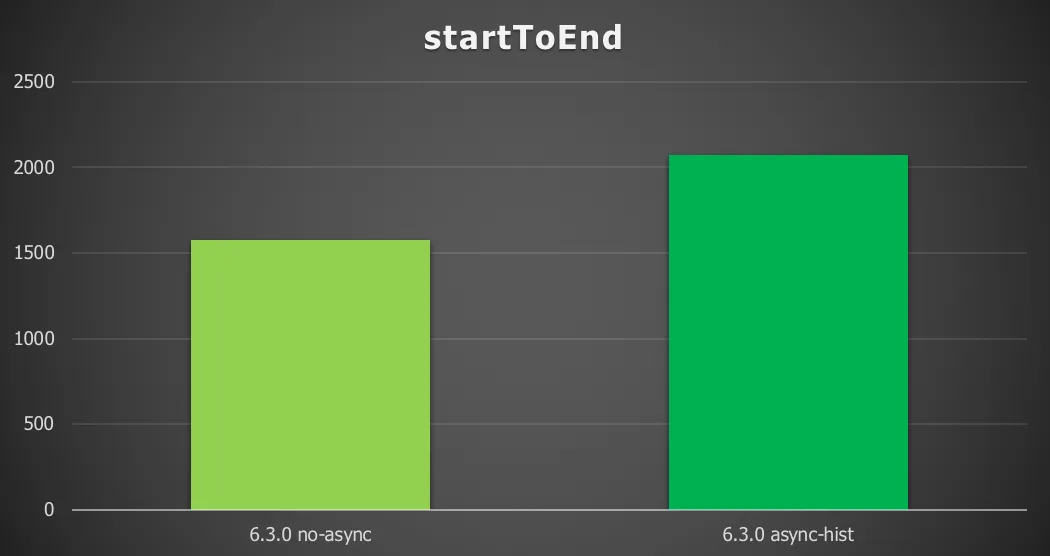
Chart 1: Start to end with a remote database and async history
Enabling async history for the simplest process definitions gives a 32 % increase in throughput (process instances/second).
The second process definition tested was the straight-through process with 10 sequential service tasks:
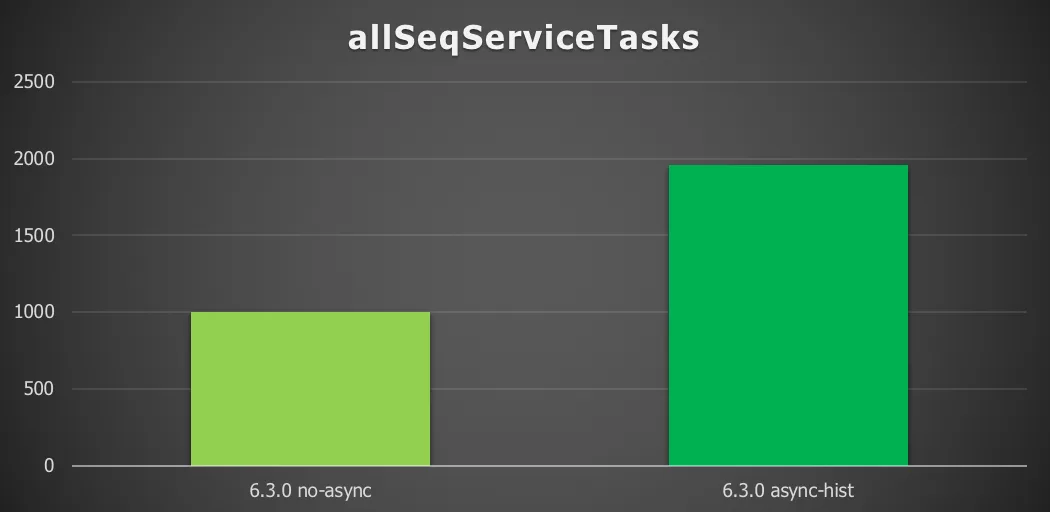
Chart 2: 10 sequential service tasks with a remote database and async history
Enabling async history gives a 96% increase in throughput (process instances/second). The big difference is due to the fact that that in one transaction here the history of 10 tasks needs to be persisted. Doing that asynchronously helps a lot. One interesting thing here is that the asynchronous result is very close to the startToEnd one above, which is logical as both persist the same amount of data at runtime. The only difference are the service invocations, which are fast.
So, people looking for (micro-)service orchestration take note: the asynchronous history feature effectively bundles all the history together and this benefits the automatic service tasks greatly.
The third process definition benchmarked was the process with 50 process variables and a few exclusive gateways:
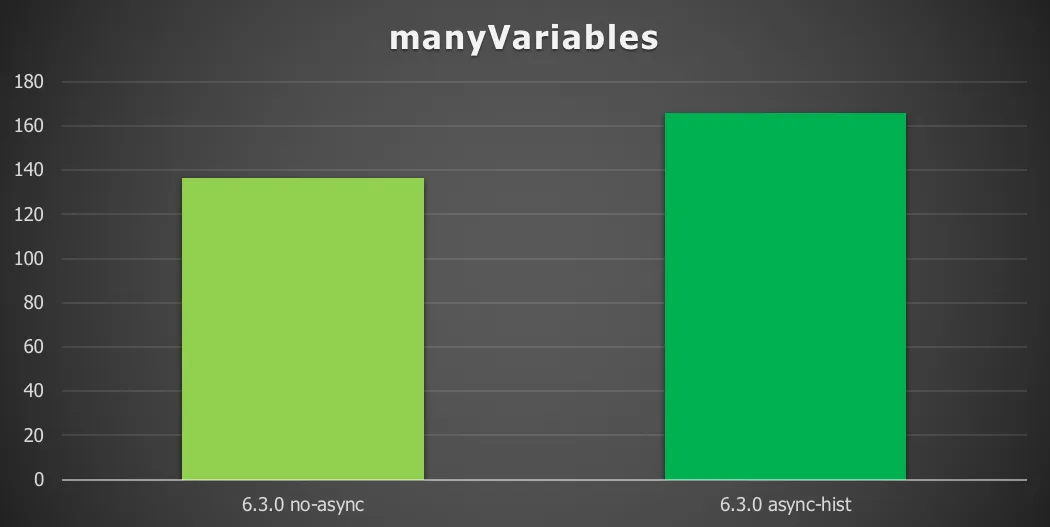
Chart 3: Many variables with a remote database and async history
Enabling async history gives here a 21% increase in throughput (process instances/second). The reason why the percentage is lower than the previous result (while having more data) is because instead of one transaction, the results here actually encompass three transactions (starting the process instance and providing 20 variables, a task query and task complete with 30 variables). The Flowable engine will insert data entities of the same type in bulk, there’s actually only one network roundtrip to the database for the batch of 20 and 30 variables.
The fourth process definition tested parallel and nested subprocesses:
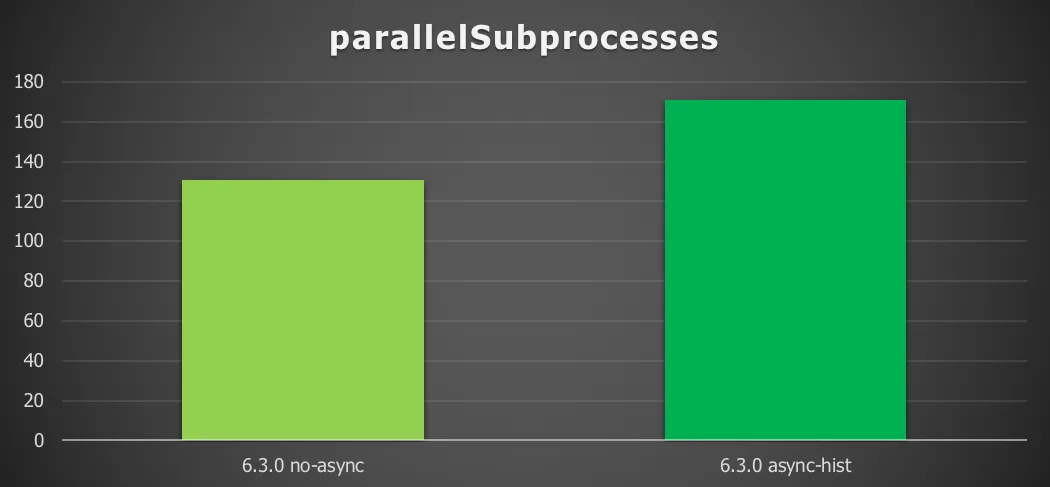
Chart 4: Parallel subprocesses with a remote database and async history
Enabling async history here gives a 31% increase in throughput (process instances/second).
The fifth and final process definition tested uses a terminate end event to stop a process instance in the middle of its execution:
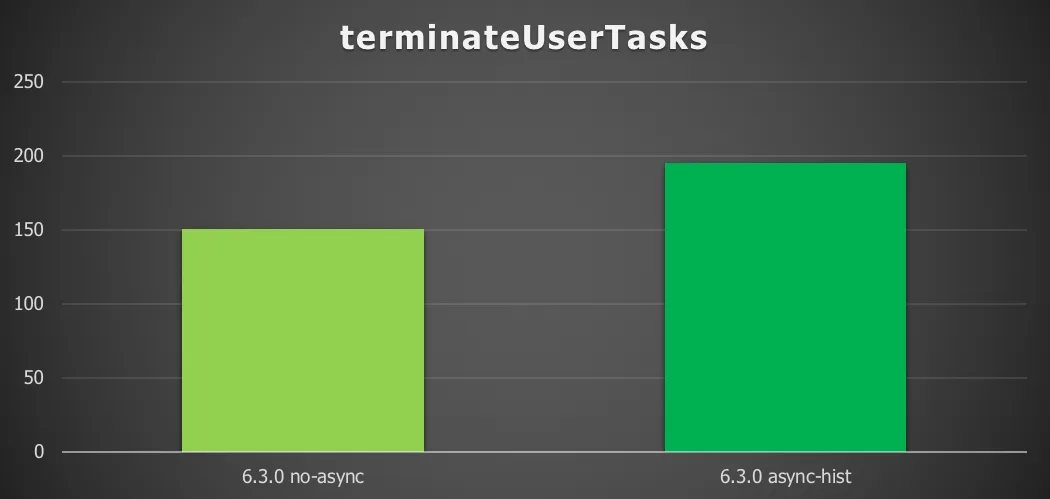
Chart 5: Terminate tasks with a remote database and async history
Enabling async history gives 30%increase in throughput (process instances/second).
Given the results, it’s quite safe to claim that asynchronous history is a great feature that boosts the throughput of the Flowable engine even more in real world scenarios. Of course, keep in mind that the base performance without asynchronous history is already great, as shown in our previous post … but it’s nice to have this reassuring feeling that Flowable has your back in case you need to scale even further!


Tools like ChatGPT can handle a variety of business tasks, automating nearly everything. And it’s true, GenAI really can do a wide range of tasks that humans do currently. Why not let business users work directly with AI then? And what about Agentic AI?

In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.
In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.