
Many process and case elements in Flowable have a property named “Asynchronous”. Although this property has a huge impact on the performance, reliability and even in the end-user experience, it is often ignored or unacknowledged. This blog is aimed to help modelers and developers understand its importance.
Many colleagues who specialize in process modeling think the same as I did when I saw this flag for the first time:
“Asynchronous means it’ll be executed later in the background, so the process will continue executing other steps“.
In reality, this is wrong (or just partially correct):
“Asynchronous means it’ll be executed later in the background (true), so the process will continue executing other steps (false)”.
The process semantics are not affected by this flag. The execution order remains unaltered.
See the process model below: Async Task 1 will be executed always before Async Task 2, regardless of the Asynchronous flag value. If the process requires some kind of parallelism, this must be achieved by modelling it with elements such as Parallel Gateways.
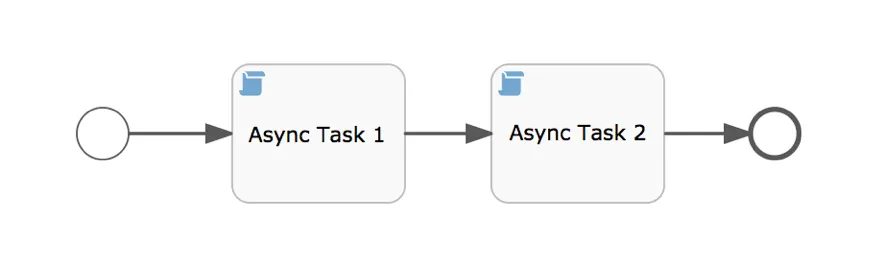
If you want to see it in action, import this example app. See how the process “Process Two Async Tasks” is designed. Both Script Tasks just write a line to the log.
Even though the first task is marked as asynchronous, the second task won’t ever be executed before the first one. Just start the process and see what the log shows:
Hello from Task1 Hello from Task2
Try as many times as you wish – but just remember that time is a precious resource.
The Flowable engine is designed to sequentially execute steps in a process or a case until it reaches a wait-state or the process is completed. This wait state can be a User Task, an Intermediate Message Event or a Timer. From the low-level engine perspective, the sequential execution is done by the same thread until that wait state is reached. From the database perspective, all changes in the process/case state belong to the same transaction, so those changes will be persisted only when the sequential execution is finished.
A step (for example, a Service Task) marked as asynchronous is also considered a wait state. As soon as the engine reaches this Service Task, instead of executing it, the process execution will be suspended and two types of information will be written to the database in the same transaction:
A new Job to resume the process execution starting from the Service Task
The process state (variables written, steps already executed, and so on)
After the transaction is committed, these changes will be now visible for other components of the process engine. As a consequence of the first of these, the new Job can be found by the Asynchronous Job Executor, therefore the Job that resumes the process execution from the Service Task will be executed asynchronously by some thread belonging to the Asynchronous Job Executor. Please note that the Job doesn’t only execute the Service Task, but also the following steps.
As a side note, by default the flowable engine has a retry mechanism for these asynchronous jobs. This means if the execution fails the first time, it will be attempted again a while later, for a total of 3 attempts (this number is configurable parameter asyncExecutorNumberOfRetries). This feature is particularly useful when calling remote services, as they might be temporarily down or unreachable due to network issues. In case of such events, this mechanism can mitigate some of those failures.
The second type of information, saving the process state, is quite important. Remember that we saved all the changes of the process execution, because all of them were attached to the same database transaction. This aspect is of the utmost importance, especially if any Exception occurs during the execution, because then the database transaction will be rolledback, so all changes done by the execution will be reverted. After this rollback, the process state will be exactly the same as before the execution was started, meaning all process steps of the failed transaction will have to be executed again by the engine.
Let’s see the impact of this with a practical example.
This is a simplified version of a pizza ordering process:
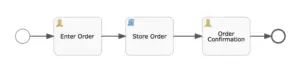
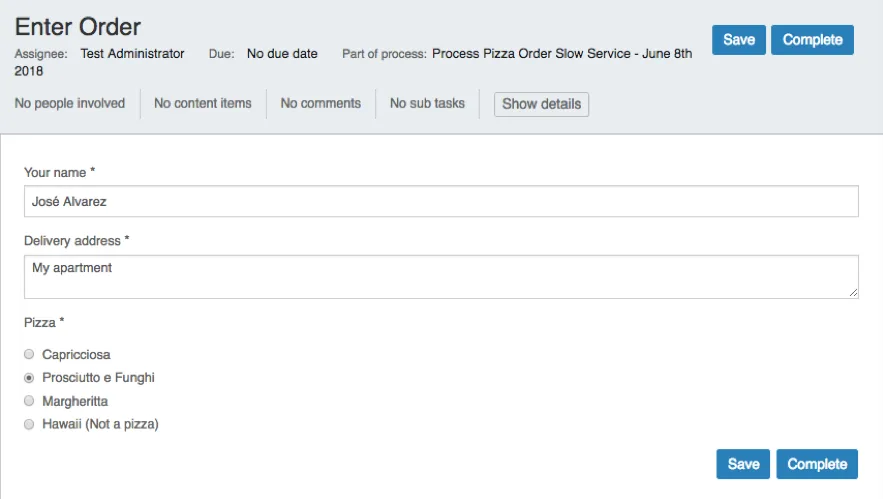
The first User Task form could look like:
In order to simulate the interaction with the pizza shop system we have a simple Script Task. We’ll see more of it later, but for now just assume that it places the order to the shop.
After the order has been successfully captured by the Script Task, a new User Task showing a confirmation will be shown:
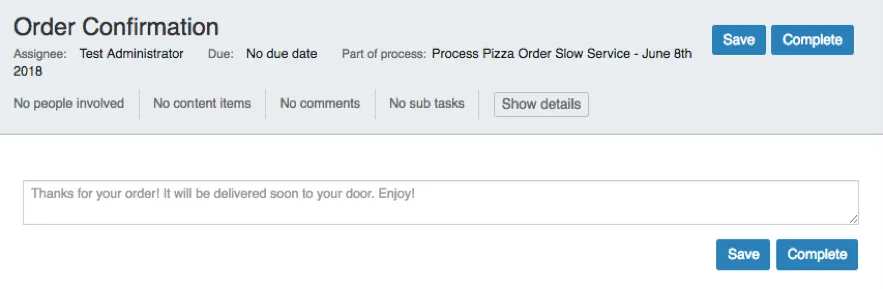
In Flowable Task, once the App has been published, the process will be started as soon as the button is pressed:

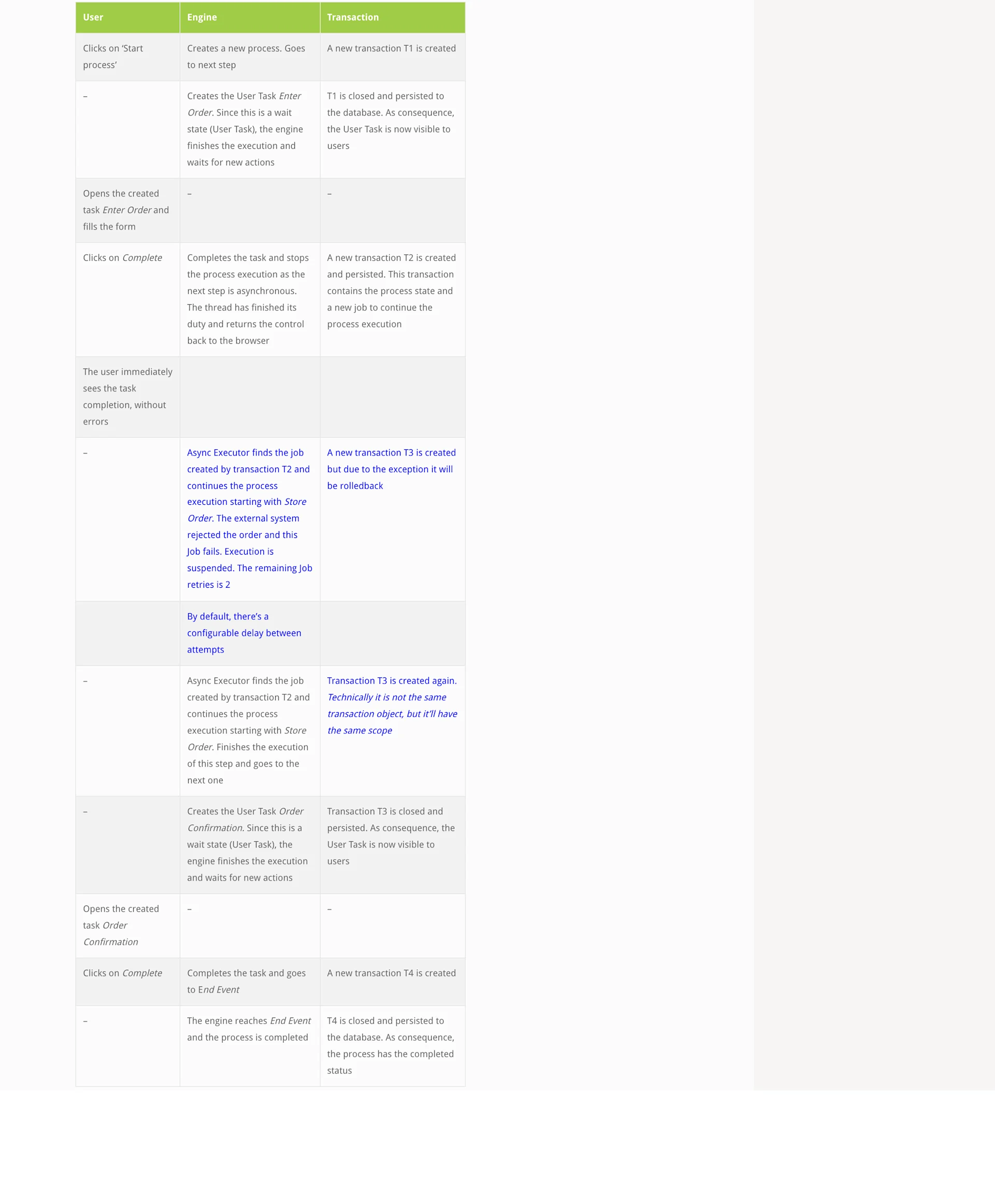
The table below will show the execution from multiple point of views: user, engine and database. This would be the happy path:
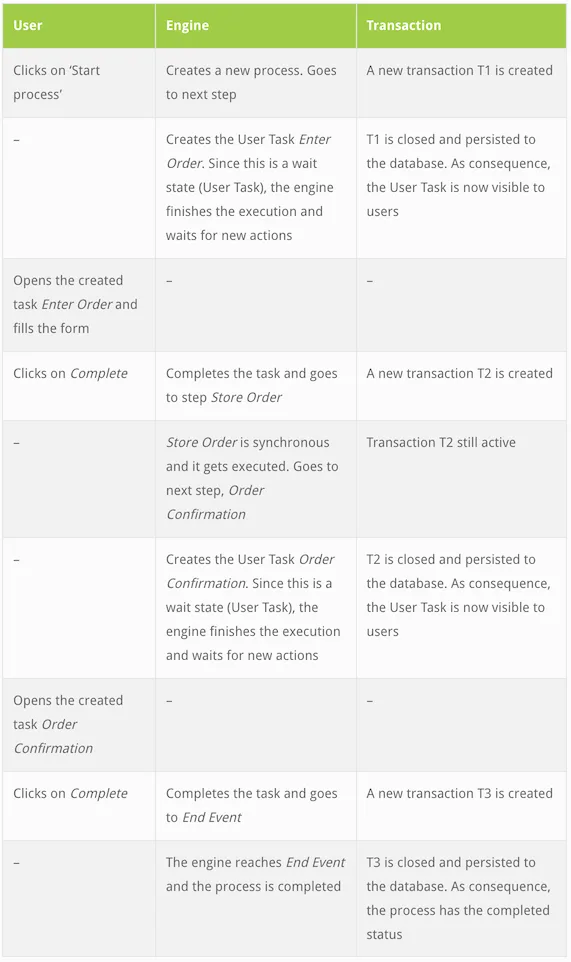
The following diagram displays the transactions:
So far, from the happy path perspective, everything worked: the customer created an order, the system registered it and a confirmation was shown to the user.
Result: Happy customer.
What if … the system responsible for capturing the orders wasn’t so reliable? Or the internal network was down at that time? We can simulate these conditions with this code for the Script Task:
if (Math.random() > 0.8) {
println "Failure sending order!"
throw new RuntimeException("Failure!")
} else {
println "Order sent"
}The new execution table is as follows, the changes compared to the happy path table have been highlighted:
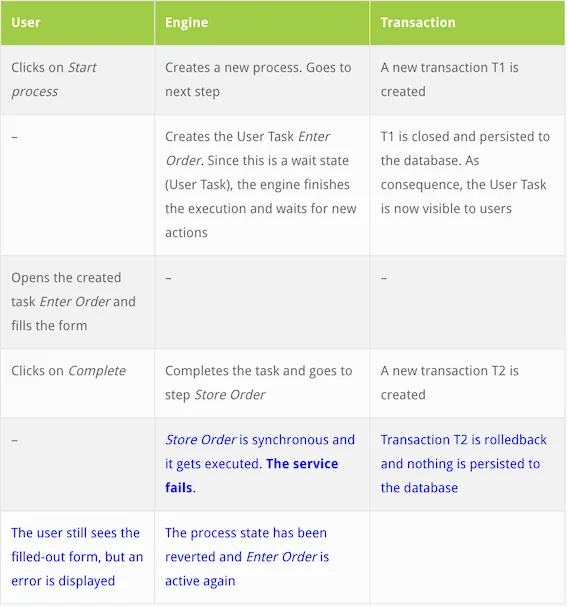
And the corresponding transactions diagram:
At this point, and depending on the frustration level, the user might click a second time on Complete. Even if it works this second time, the pizza company has already lost: the best case is that the user noticed the page is unreliable, leaving an unprofessional impression. The worst case is that the customer closed the browser and never came back.
Result: customer lost / unprofessional appearance.
Now let’s assume that the capturing order system is reliable but slow (ever experienced that when ordering online?). Let’s say it takes around 30 seconds to confirm the order. The result is shown below:
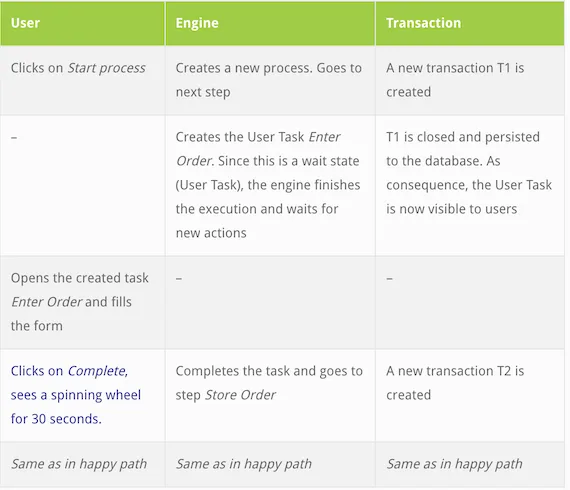
The transactions are exactly the same as in the happy path, with T2 being considerably slower:
Your customer got nervous when the browser displayed a spinning wheel for so long, and noticed that your system is slow.
Result: Bad user experience. The system (and hence your company) doesn’t look professional!
Having no tasks marked as asynchronous means that the process steps will be immediately called one after another. This is not suitable when calling 3rd party systems, as delays and failures can directly affect the customer.
As explained above, when the engine reaches an asynchronous step, the process state is saved to the database, then the process execution will be resumed later by some other thread. This sounds promising for our current problem: if we save the state after the customer submits the order, it’s safe to say that the order has been received (persisted) and no further customer action is required.
It seems pretty clear that the second step of our process (Store Order) should be marked as asynchronous. Let’s do it and evaluate the execution as we did before.
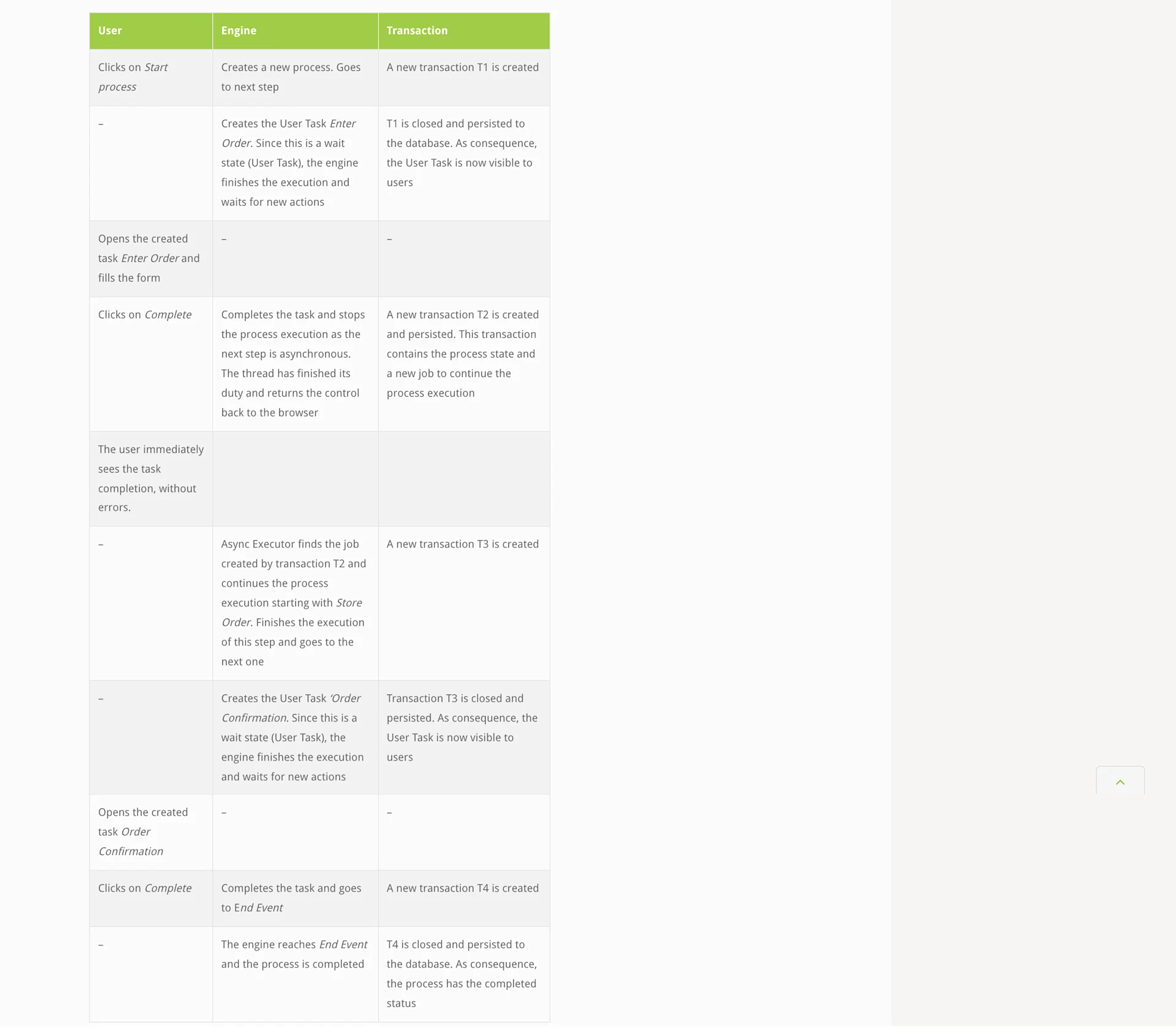
As expected in the happy path, everything worked smoothly: the order is quickly stored and a confirmation task created as soon as the order was processed. Now we can start thinking about improving our process; in fact, instead of using a User Task to model the confirmation, an email could be sent. This will make the overall process more pleasant to the customer, as there would be no need to refresh the page to get a confirmation User Task.
Result: Happy customer.
Just as before, the ordering system is overloaded and seems to reject some orders by throwing an exception. A possible sequence of events is that the first time around, the order is rejected but the second time it is accepted. This table represents the flow (highlighted cells show the changes compared to happy path table):
Model view:
The sequence above was impressive: even when a problem happened behind the scenes, the user didn’t notice it at all! The engine overcame the low availability of the remote system. Remember the synchronous approach? The user not only saw the error, he was also responsible for deciding what to do next, and therefore responsible for the whole process! She had to decide whether she should complete the task again or forget everything.
In contrast to the synchronous model, the asynchronous approach shifts the responsibility from the user to the engine. If the system fails, it is the engine that decides what to do next and how to overcome such failures.
Result: Happy customer. No errors were shown, she received the pizza. The only effect of the failure is a slight delay in the overall process. Probably something the customer didn’t notice. In fact, the delay in this case is the configured value of the time between retries.
In this scenario, the sequence of events and activities are exactly the same as in the happy path. The only difference is that the transaction T3 will take longer because of the ordering system’s poor performance. However, that’s something that doesn’t matter very much, as the first User Task completes almost instantly and the customer won’t perceive the system slowness.
Result: Happy customer. No errors were shown, she received the pizza. The lack of performance of the ordering system does still affect the overall duration, but if the average delivery time is around 15 minutes, 30 seconds deviation won’t affect customer satisfaction.
This blog post aimed to provide a better understanding of the asynchronous flag. The examples demonstrate what I promised in the introduction: that performance, reliability and user experience can be improved drastically when it is applied after some process analysis.
This flag is not a magic wand though, there are some use cases where a synchronous process is needed: for example, when removing user permissions from a system, due to security reasons, the system administrator requires immediate feedback. For most of the cases, if the user doesn’t strictly need this, setting the asynchronous flag helps reduce the length of transactions, keeping the process executions short, and even helps distributing the load among a cluster.
More information:
Link to Demo App
https://www.flowable.org/docs/userguide/index.html#bpmnConcurrencyAndTransactions
https://www.flowable.org/docs/userguide/index.html#_async_executor

Tools like ChatGPT can handle a variety of business tasks, automating nearly everything. And it’s true, GenAI really can do a wide range of tasks that humans do currently. Why not let business users work directly with AI then? And what about Agentic AI?

In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.
In this post, we continue our exploration of workflow complexity - learn how key metrics like activity count and control flow reveal natural groupings of models, making it easier to identify and improve overly complex designs.
